Pythonで人気の外部ライブラリのひとつ「Pandas」のデータ結合についての使い方をご紹介します。
具体的には「concat」メソッドをもちいて、複数のデータフレームをひとつにまとめる方法をご説明します。
例えば、年間の売上データを編集したいと思っても、それぞれ月毎に売上データが別々に保存されている場合などがあるとします。そういった場合には、まず月々の売上データをひとつのデータに集約してから作業をおこなう必要があります。
このような場面で「concat」メソッドを活用できるようになれば、月々の売上データを一括して集約することができるかもしれません。
こちらでは、具体的なExcelファイルをつかった作業をとおして「concat」メソッドの活用方法をご紹介します。もしデータの追加方法についてご興味がありましたら是非ご一読ください。
基本操作|Excelデータの統合
先ほどご紹介した「concat」メソッドをもちいた売上データの統合方法をご説明します。
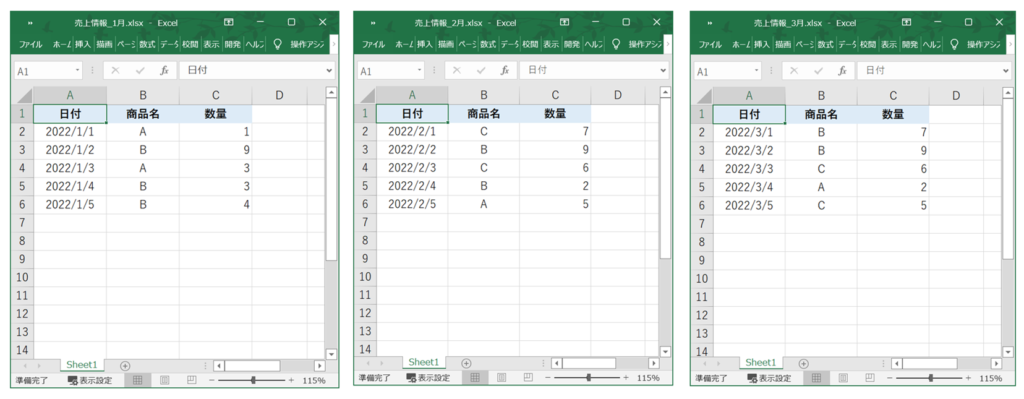
まずは使用するデータの内容を確認します。 データ統合の例として、3つのExcelファイルに掲載されている1月~3月の月次売上データを使用します。
具体的には、こちらのExcelファイルを使用します。
それぞれのExcelファイルには、「日付」「商品名」「数量」の順に、おなじ列名のデータが格納されています。
- 売上情報_1月.xlsx
- 売上情報_2月.xlsx
- 売上情報_3月.xlsx
先にプログラムの実行結果を確認しましょう。
こちらが実行結果です。
1月~3月の月次売上データがひとつのデータに統合されていることが確認できます。
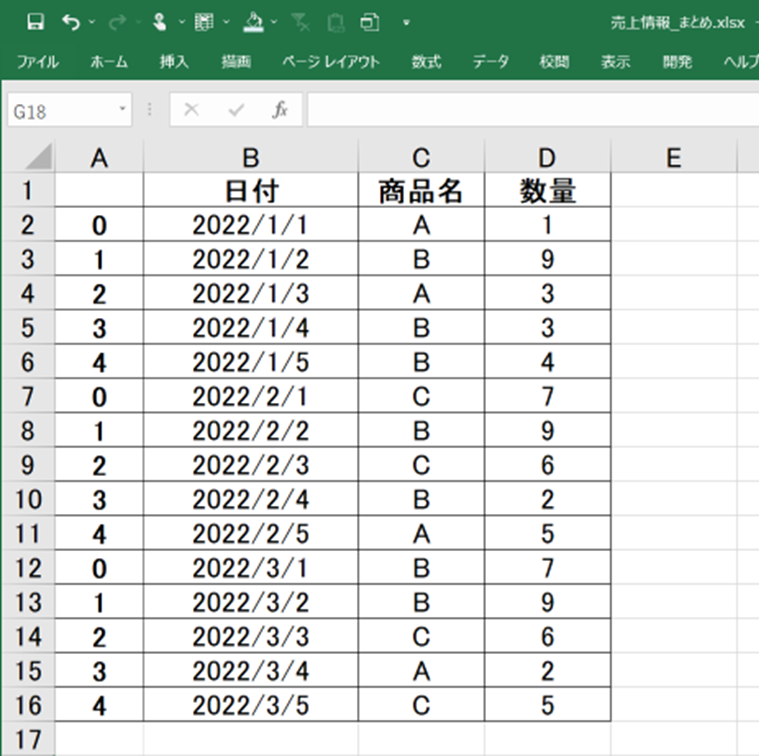
表示の都合上、罫線などはExcelファイル上で編集をしています。
こちらが上記でご紹介した内容のコードです。
import pandas as pd
df_sale_1 = pd.read_excel(""売上情報_1月.xlsx"")
df_sale_2 = pd.read_excel(""売上情報_2月.xlsx"")
df_sale_3 = pd.read_excel(""売上情報_3月.xlsx"")
df = pd.concat([df_sale_1, df_sale_2, df_sale_3])
df.to_excel(""売上情報_まとめ.xlsx"") おおまかなプログラムの流れは以下のとおりです。
- 「Pandas」のインポート
- 売上情報のExcelファイルを読込
- 読み込んだExcelファイルを統合
- 新規でExcelファイルを作成
具体的な手順は以下のとおりです。
手順1|「Pandas」のインポート
import pandas as pd
まずは外部ライブラリの「Pandas」をインポートします。
慣習的にライブラリ名を「pd」としています。
手順2|売上情報のExcelファイルの読込
df_sale_1 = pd.read_excel(""売上情報_1月.xlsx"")
df_sale_2 = pd.read_excel(""売上情報_2月.xlsx"")
df_sale_3 = pd.read_excel(""売上情報_3月.xlsx"")統合元となるExcelファイルを取り込んで変数に代入します。
取込方法は「read_excel」を使用しますが、指定するファイル名の記述では拡張子(「.xlsx」など)を明記しましょう。
手順3|読込済のExcelファイルの統合
df = pd.concat([df_sale_1, df_sale_2, df_sale_3])
取込済みのExcelファイルを統合します。
「concat」メソッドをもちいて対象となる3つの変数を指定します。
変数を指定する際は、「[](記号:角カッコ)」をつかってリスト型として値を引き渡します。
手順4|新規Excelファイルの作成
df.to_excel("売上情報_まとめ.xlsx")Excelファイルを新規で名前を付けて保存します。
上記例ではファイル名「売上情報_まとめ.xlsx」としていますが、既におなじ名前のファイルがある場合は上書保存されますのでご注意ください。
スポンサーリンク
基本構文|concatメソッド
「concat」メソッドの詳しい使い方をご紹介をします。
構文は以下のとおりです。
pandas.concat(objs, axis=0, join='outer', ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=True)
| 引数 | 内容 |
| objs | 連結の対象となる「Series」もしくは「DataFrame」を指定 |
| axis | 「0」か「1」を入力して連結基準を指定(「0」はindex基準、「1」はcolums基準) ※省略可(省略した場合は「0=index」) |
| join | 「inner」か「outer」を入力して連結基準を指定(「inner」は内部結合、「outer」は外部結合) ※省略可(省略した場合は「inner」の内部結合) |
| ignore_index | 「True」か「False」を入力して連結基準を指定(「True」は新たなインデックス番号を採番、「False」は連結元のインデックス番号を使用) ※省略可(省略した場合は「False」) |
| keys | 「keys」で指定した階層でインデックス番号を分割します。 ※省略可 |
| levels | MultiIndexの構築に使用するレベルを指定します。 レベルは、MultiIndexのなかの階層を指定する際に『「階層名」もしくは「階層番号(一番左は「0」)」』をもちいて指定します。 ※省略可(省略した場合は「keys」より推測される) |
| names | 階層インデックスに対して名前指定します。 ※省略可 |
| verify_integrity | 「True」を入力することによって、インデックスに重複が含まれていないかどうかを確認します。 ※省略可(省略した場合は「False」) |
| sort | 「True」を入力することによって、非連結軸をソートします(結合が「join=”outer”」の場合にのみ有効)。 ※省略可(省略した場合は「False」) |
| copy | 「False」を入力することによって、メモリ効率化のためにオブジェクトから常にデータをコピーしないようにします。 ※省略可(省略した場合は「True」) |
「MultiIndex」とは、「Series(一次元)」や「DataFrame(二次元)」のデータ構造におけるインデックスラベルが階層的になったもののことです。
具体的には、こちらのような形でインデックスが「階層的」に設定されている状況です。
こちらの例では、イメージをつかむため「DataFrame(二次元)」での表示ではありますが、「階層1」→「階層2」→「階層3」の順でインデックスごとにデータが構造化されています。
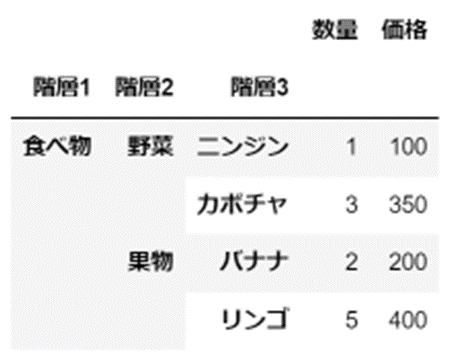
「MultiIndex」とは、このようなデータ構造を格納・操作するためのデータの形のことです。
ちなみに、先ほどご紹介した「DataFrame(二次元)」の例を、「MultiIndex」で出力した場合の表示はこのような形になります。
MultiIndex([('食べ物', '野菜', 'ニンジン', 1, 100),
('食べ物', '野菜', 'カボチャ', 3, 350),
('食べ物', '果物', 'バナナ', 2, 200),
('食べ物', '果物', 'リンゴ', 5, 400)],
names=['階層1', '階層2', '階層3', '数量', '価格'])
各引数の使い方
「concat」メソッドの引数の使用方法についてご説明をします。
objs
結合の対象となるデータを指定します。
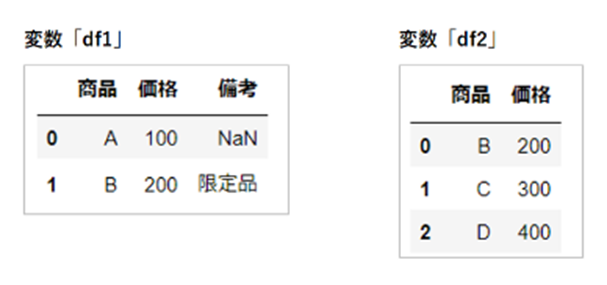
まずは、結合の対象となるデータを読み込みます。
df1 = pd.read_excel("sample1.xlsx")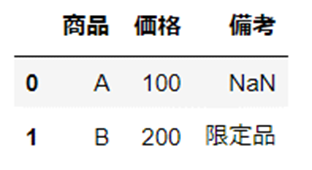
df2 = pd.read_excel("sample2.xlsx")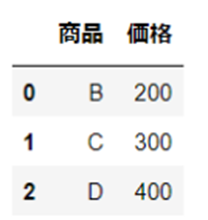
つぎに、引数「objs」を指定します。
指定方法はこちらのとおり、リスト形式で「concat」メソッドにそれぞれの変数を引き渡します。
なお、こちらの例では2つの引数「df1」「df2」を指定していますが、3つ以上の引数を指定することも可能です。
df = pd.concat([df1, df2])
axis
「行基準」もしくは「列基準」で結合方法を指定します。
引数「axis」を「1」とした場合、「列基準」での結合となります。
引数「axis」を省略した場合、「0」の「行基準」として認識されます。
こちらの2つのデータを引数「axis」の「列基準」をつかって結合します。
こちらが実行結果です。
「列基準」での結合のため、横方向にデータが結合されていることが確認できます。
df_axis = pd.concat([df1, df2], axis=1)
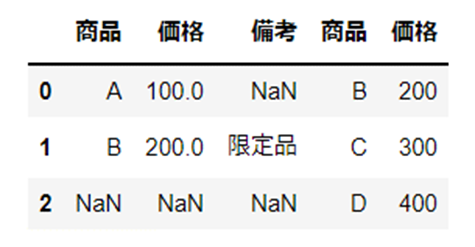
join
引数「join」を使うことによって、連結基準を指定することができます。
指定できる連結基準は、「inner」と「outer」の2パターンです。
こちらの2つのデータをもちいて使用方法をご紹介します。
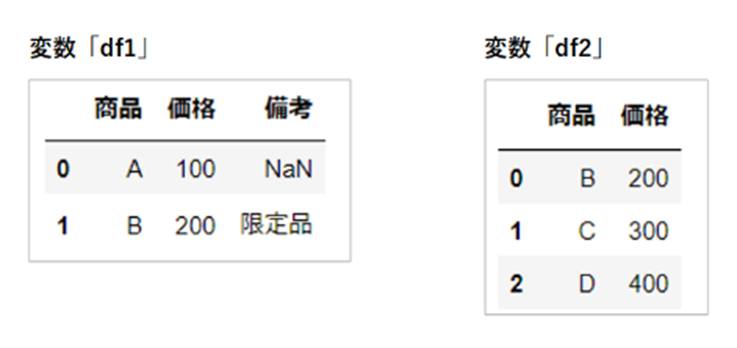
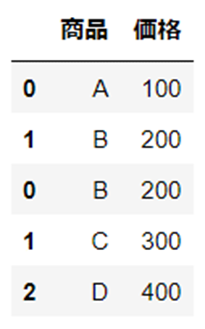
まず、連結基準「inner」を使用します。
変数「df1」に含まれている列名「備考」が、結合後のデータには掲載されていないことが確認できます。
「inner」を使用した場合、結合対象となるデータに共通する列名だけが結合されるためです。
df_join_in = pd.concat([df1, df2], join="inner")
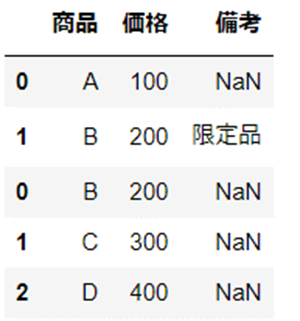
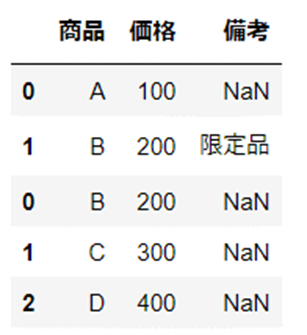
つぎに、連結基準「outer」を使用します。
2つの結合対象に含まれる列名すべてが結合されていることが確認できます。
df_join_out = pd.concat([df1, df2], join="outer")
ignore_index
引数「ignore_index」をつかってインデックス番号の採番方法を指定することができます。
こちらの2つのデータをもちいて使用方法をご紹介します。
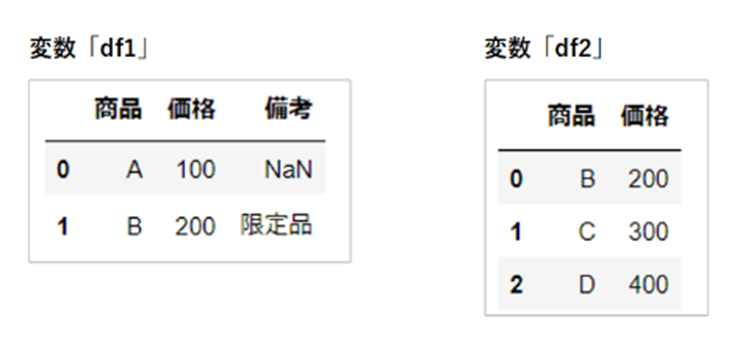
引数「ignore_index」は、「True」か「False」で指定します。
まずは、「False」とした場合を確認します。
それぞれの変数「df1」「df2」のインデックス番号が変更されることなく結合されています。
(引数「ignore_index」を省略した場合は、「False」が指定されたものとして認識されます。)
df_ign = pd.concat([df1, df2], ignore_index=False)
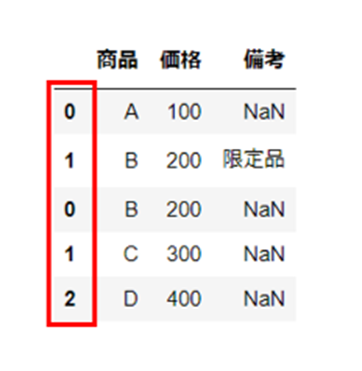
つぎに、「True」とした場合を確認します。
それぞれの変数「df1」「df2」のインデックス番号が変更されていることが確認できます。
結合後のデータにたいして、新しい連番が割り振られています。
df_ign = pd.concat([df1, df2], ignore_index=True)
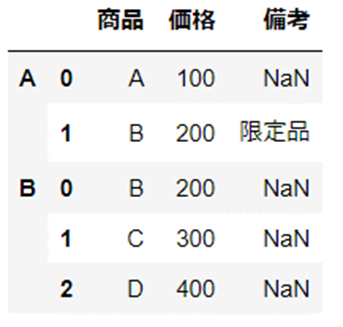
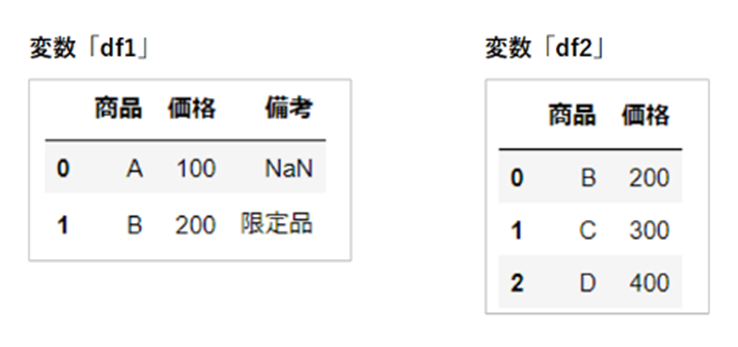
keys
インデックス番号を引数「keys」で指定した値で分割することができます。
こちらの2つのデータをもちいて使用方法をご紹介します。
以下のとおり、引数「keys」にリスト型で値を引き渡しています。
引き渡した値によってインデックス番号が分割されていることが確認できます。
df_keys = pd.concat([df1, df2], keys=["A", "B"])