Pythonを使ったのデータ分析では非常に強力な方法のひとつである「Pandas」の基本的な使い方を初心者向けに解説しています。
データ編集において「Pandas」を使えるようになれば、Pythonでできることの幅が広がります。はじめての場合は、まずはこちらをご覧のうえ、サンプルデータの編集などを通して実際に操作していただくことをオススメします。
Pandasとは
「Pandas」とは、おもに表形式データの集計や操作を直感的にできるように設計されたPythonのパッケージです。Pythonの「サードパーティライブラリー」として提供されていますので、インストールすればすぐに使い始めることができます。
なお、「サードパーティライブラリー」とは、Pythonにあらかじめ機能として備わっている「標準ライブラリー」とは別に、外部サイトからインストールすることによってPythonの機能を拡張するためのファイルのことです。
ちなみに、「サードパーティ」とは「第三者」を意味します。
Pandasを使ってできること
「Pandas」をうまく使うことによって、高度なデータ分析を実現することができます。
例えば、Excelの「sum関数」や「sumifs関数」のような機能を持っていて、表形式データをかんたんに集計することができます。
また、表形式データの操作面では、行列の編集だけでなく、複数のデータ同士を結合してひとつにまとめることや、リレーションシップによる複数データの関連付をすることが可能です。
その利便性の高さから、機械学習などであつかうデータの「前処理」と呼ばれる「データをきれいに整形する工程」において「Pandas」が使われるケースもあります。
なお、この場合の「データをきれいに整形する工程」とは、コンピューターがデータを有効活用しやすくするための作業を指します。
ざっくりではありますが、「前処理」には具体的にこのような工程があります。
- さまざまなファイルに散らばっている必要なデータを集めて関連付する
- データに含まれる欠損値(未記入などによるデータの欠落)を補完する
- データ分析に必要な情報を抽出する
スポンサーリンク
Pandasのはじめ方
「Pandas」は「サードパーティライブラリ」に分類されるため、「Pandas」を使い始めるにあたっては外部からのインストールが必要です。
まずは、管理ツールの「pip」をつかってコンピューターに「Pandas」をインストールをします。
pip install pandasつぎに「サードパーティライブラリ」を使える状態にするために「Pandas」を「import」します。
「import」の方法はこちらです。
ソースファイルの先頭に記述しましょう。
import pandas as pd
ちなみに、「Pandas]ではプログラムの入力を簡易にする目的で「pd」という表記で簡略化されることが多いため、こちらでもその慣習にしたがって記述しています。
以降、プログラムの記述において「pandas」を「pd」と簡略化して表記しています。
Pandasであつかうデータの種類
「Pandas」の操作対象となるデータには、「Series」と「DataFrame」の2つの種類があります。
Series
Seriesとは、1次元配列のデータ構造のことを指します。
特徴
Series の特徴はつぎの通りです。
- 直線的に1方向に対する単純なデータの配列
- 先頭から順番にデータが並んでいる
- データの順番を指定することによって値を取り出すことができる
構文
pd.Series (data=データ配列, index=行名, name=列名)具体例
test_series1 = pd.Series(data=["A", "B", "C"], index=[1, 2, 3], name="test")

以下のとおり、「index」と「name」を省略することもできます。
(「data=」という記述も省略できます。)
test_series2 = pd.Series(["A", "B", "C"])

DataFrame
DataFrameとは、2次元配列のデータ構造のことを指します。
特徴
DataFrame の特徴はつぎの通りです。
- 平面的に縦横の2方向に対するのデータの配列
- 配列のなかに配列を含んでいる
- データの縦横番号を指定することによって値を取り出すことができる
構文
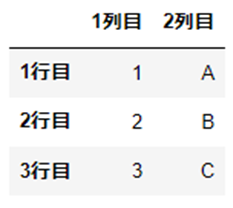
pd.DataFrame (data=データ配列, index=行名, columns=列名)具体例
test_df1 = pd.DataFrame(data=[[1, "A"], [2, "B"], [3, "C"]], index=["1行目", "2行目", "3行目"], columns=["1列目", "2列目"])
以下のとおり、「index」と「columns」を省略することもできます。
(「data=」という記述も省略できます。)
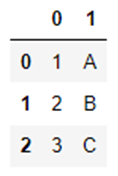
test_df2 = pd.DataFrame([[1, "A"], [2, "B"], [3, "C"]])
スポンサーリンク
Pandasの基本的な操作例
「Pandas」を使った具体的な操作例をご紹介します。
データの読み込み
外部データの読み込み方法です。
こちらでは、ExcelとCSVのデータを読み込み方法をご紹介します。
Excel
Excel ファイル「SAMPLE.xlsx」を読込対象としています。
なお、取得したExcel ファイルを変数「df」に代入しています。
df = pd.read_excel('SAMPLE.xlsx)
CSV
CSV ファイル「SAMPLE.csv」を読込対象としています。
なお、取得したCSV ファイルを変数「df」に代入しています。
df = pd.read_csv(SAMPLE.csv'
データの確認
統計情報|describe
データの統計情報を確認することができます。
df.describe()
確認できる統計情報は以下のとおりです。
| 表示 情報 | 意味 | 詳細 |
| count | データ個数 | データの個数です。 |
| mean | 平均値 | データをすべて足した合計値をデータ数で割った値のことです。 |
| std | 標準偏差 | データのばらつきの度合いを示す数値のことです。 |
| min | 最小値 | データのなかで最も小さい値のことです。 |
| 25% | 第一四分位数 | 四分位数のひとつです。データを小さい順にならべて、最初から数えて25%の位置にある数字のことです。 |
| 50% | 第二四分位数(中央値) | 四分位数のひとつです。データを小さい順にならべて、最初から数えて50%の位置にある数字のことです。データ数が偶数の場合は中央に近い2つの平均値とします。 |
| 75% | 第三四分位数 | 四分位数のひとつです。データを小さい順にならべて、最初から数えて75%の位置にある数字のことです。 |
| max | 最大値 | データのなかで最も大きい値のことです。 |
行列サイズ|shape
データの行列のサイズを確認することができます。
df.shape
例えば、3行2列のデータの場合、以下の内容が取得されます。
(3, 2)
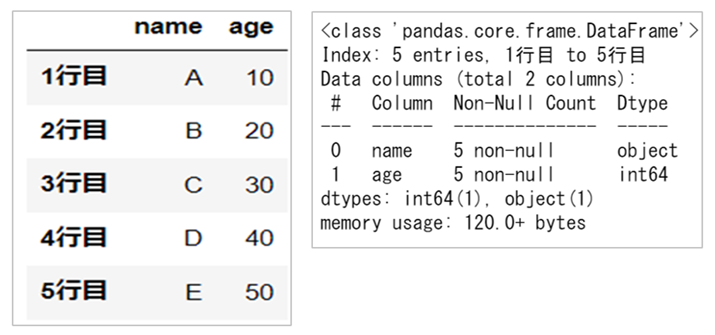
要約情報|info()
データの要約情報を確認することができます。
df.info()
例えば、左側の「DataFrame」に対して右側が表示される要約情報です。
データの抽出
基本的なデータ操作の方法についてご紹介します。
データ表示
変数「df」には「DataFrame」が代入されていますが、「Series」でも同じ結果になります。
head
データの最初の行を表示します。
引数を省略した場合は「5行分」を表示しますが、引数を指定した場合は任意の行数を表示させることができます。
df.head()
tail
データの最後の行を表示します。
引数を省略した場合は「5行分」を表示しますが、引数を指定した場合は任意の行数を表示させることができます。
df.tail()
sample
データをランダムに選択して行を表示します。
引数を省略した場合は「1行分」を表示しますが、引数を指定した場合は任意の行数を表示させることができます。
df.sample()
行列の指定
特定の行列の指定方法について、こちらのデータをつかってご説明します。
df = pd.DataFrame([["A", 10], ["B", 20], ["C", 30], ["D", 40], ["E", 50]], index=["1行目", "2行目", "3行目", "4行目", "5行目"], columns=["name", "age"])
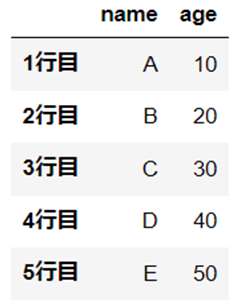
データを操作して実際にお試しいただくことをオススメします。
loc
「行名」や「列名」を指定することによってデータを表示します。
「行名」をつかって指定する場合
行名を入力することによって行を指定します。
なお、記号「:(コロン)」を入力することによって列情報「すべて」を指定しています。
df.loc("[任意の行名, :]")
行名「5行目」を指定した場合の結果です。
df.loc["5行目", :]
name E
age 50
Name: 5行目, dtype: object
「列名」をつかって指定する場合
列名を入力することによって列を指定します。
なお、記号「:(コロン)」を入力することによって行情報「すべて」を指定しています。
df.loc("[:, 任意の列名]")
列名「age」を指定した場合の結果です。
df.loc[:, "age"]
1行目 10
2行目 20
3行目 30
4行目 40
5行目 50
Name: age, dtype: int64
「行名」と「列名」をつかって指定する場合
行名と列名を入力することによって特定データを指定します。
df.loc("[任意の行名, 任意の列名]")
行名「2行目」、列名「age」を指定した場合の結果です。
df.loc["2行目", "age"]
20
「範囲指定」する場合(スライス)
記号「:(コロン)」を使うことによって範囲指定することができます。
ちなみに、このように開始と終了の範囲指定をして該当部分を取得する機能のことを「スライス」と呼びます。
df.loc("[任意の開始行名, 任意の終了行名, :]")
行名「2行目」から「4行目」を指定した場合の結果です。
df.loc["2行目":"4行目", :]
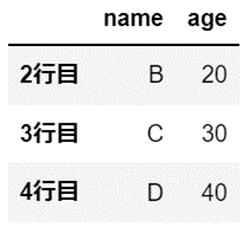
「列名」も同様の考え方で指定します。
iloc
「インデックス」を入力することによって「行番号」や「列番号」を指定します。
「インデックス」とは行や列を表す番号のことで、「1」からではなく、「0」から始まることが特徴です。
「行番号」をつかって指定する場合
行番号を入力することによって行を指定します。
df.iloc("[任意の行番号, :]")行番号「1」を指定した場合の結果です。
df.iloc[1, :]
name B
age 20
Name: 2行目, dtype: object
行番号で「1」を指定している場合であっても、「1行目」ではなく「2行目」が出力されていることがポイントです。
「列番号」をつかって指定する場合
列番号を入力することによって列を指定します。
df.iloc("[:, 任意の列番号]")
列番号「0」を指定した場合の結果です。
df.iloc[:, 0]
1行目 A
2行目 B
3行目 C
4行目 D
5行目 E
Name: name, dtype: object
列番号で「0」を指定することによって「1列目」を取得しています。
「行番号」と「列番号」をつかって指定する場合
行番号と列番号を入力することによって特定データを指定します。
df.iloc("[任意の行番号, 任意の列番号]")行番号「1」から「3」を指定した場合の結果です。
df.iloc[1:3, :]

抽出の対象となる範囲は、「1」から「3まで(未満)」となり、列番号「3」に該当する列名「4行目」は含まれていません。
ちなみに、こちらが抽出前のデータです。
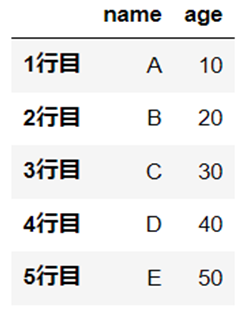
「列番号」も同様の考え方で指定します。
抽出範囲の指定は紛らわしいポイントですので、しっかりおさえておきましょう。
行列の条件抽出
特定の行列の指定方法について、こちらのデータをつかってご説明します。
df = pd.DataFrame([["A", 10], ["B", 20], ["C", 30], ["D", 40], ["E", 50]], index=["1行目", "2行目", "3行目", "4行目", "5行目"], columns=["name", "age"])
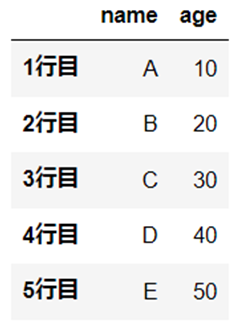
単数条件の指定
任意の条件に基づいてデータ抽出ができます。
DataFrame「df」のなかで、条件「”age”が30より下」を指定しています。
df[df["age"] < 30]
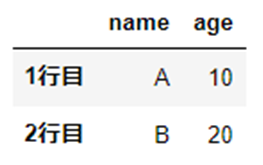
ちなみに、条件設定の段階で「True」となっている分がデータ抽出の対象です。
(「False」となっている分は抽出されません。)
df["age"] < 30

複数条件の指定
複数条件の設定方法はこちらです。
条件設定のために記号を使用します。
「or」などの理論式を使うとエラーになりますので、以下の記号を使いましょう。
| 記号 | 意味 |
| & | 「AかつB」のように「and」とおなじ使い方をします。 |
| | | 「AもしくはB」のように「or」とおなじ使い方をします。 |
| ~ | 「AでもBでもない」のように「not」とおなじ使い方をします。 |
出力結果が「True」となっている分がデータ抽出の対象です。
「”age”が30より下」かつ「”name”が”A”」を抽出対象としています。
df[(df["age"] < 30) & (df["name"] == "A")]

「”name”が”A”でない」かつ「”name”が”B”でない」を抽出対象としています。
~(df["name"] == "A") & ~(df["name"] == "B")

行列名の変更
こちらのデータをつかって行名・列名の変更方法をご説明します。
df = pd.DataFrame([["A", 10], ["B", 20], ["C", 30], ["D", 40], ["E", 50]], index=["1行目", "2行目", "3行目", "4行目", "5行目"], columns=["name", "age"])
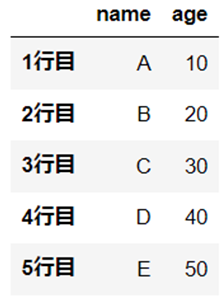
行名の変更
「index」をつかって行名を変更します。
df.rename(index={"1行目":"一行目"})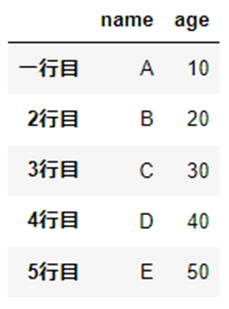
列名の変更
「columns」をつかって列名を変更します。
df.rename(columns={"name":"名前"})
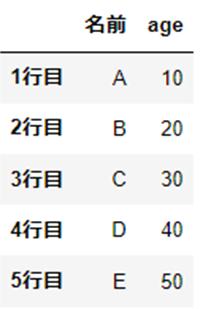
行列名の変更
複数の行列を指定することや、行名・列名を一度に変更することができます。
df.rename(index={"1行目":"一行目", "2行目":"二行目"}, columns={"name":"名前", "age":"年齢"})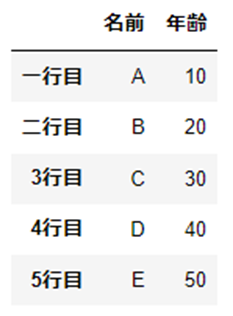
行列の追加
特定の行列の指定方法について、こちらのデータをつかってご説明します。
df = pd.DataFrame([["A", 10], ["B", 20], ["C", 30], ["D", 40], ["E", 50]], index=["1行目", "2行目", "3行目", "4行目", "5行目"], columns=["name", "age"])
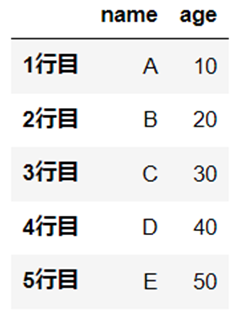
行の追加
追加対象となるあらたな「行名」と「値」を指定します。
行名「6行目」とその値を追加します。
df.loc["6行目"] = ["F", 60]
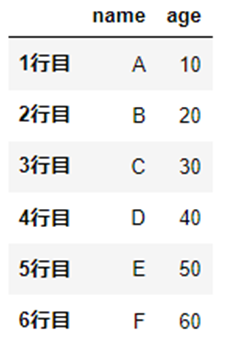
列の追加
追加対象となるあらたな「列名」と「値」を指定します。
列名「new」とその値を追加します。
df["new"] = [1, 2, 3, 4, 5]
行列の削除
行列の削除には「drop」メソッドを使用します。
引数の「axis」をつかって削除対象となる行列を区別します。
特定の行列の指定方法について、こちらのデータをつかってご説明します。
df = pd.DataFrame([["A", 10], ["B", 20], ["C", 30], ["D", 40], ["E", 50]], index=["1行目", "2行目", "3行目", "4行目", "5行目"], columns=["name", "age"])
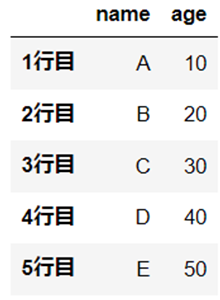
行の削除
引数の「axis」を「axis=0」とします。
df.drop("1行目", axis=0)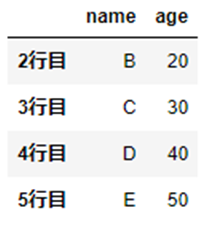
列の削除
引数の「axis」を「axis=1」とします。
df.drop("age", axis=1)
データの書き込み
外部データへの書き込み方法です。
ExcelとCSVのデータを書き込み方法をご紹介します。
Excel
df.to_excel(ファイルパス)
例えば、デスクトップにファイル名「test.xlsx」を出力する方法はこちらです。
df.to_excel(C:\Users\ユーザー名\desktop\test")
CSV
df.to_csv(ファイルパス)
例えば、デスクトップにファイル名「test.csv」を出力する方法はこちらです。
df.to_csv(C:\Users\ユーザー名\desktop\test")
スポンサーリンク
【縦方向】データの追加|concat
データを縦方向、つまり「行を追加」する方法についてご紹介します。
基本的な操作方法
pd.concat(objs)- 「objs」には「Series」もしくは「DataFrame」を代入
- 2つ以上の「objs」結合が可能
- 引数による結合方法の指定が可能
基本的な引数はこちらです。
| 引数 | 値 | 結果 | 備考 |
| objs | 「Series」or「DataFrame」 | データの結合 | 結合対象のデータを指定 |
| axis | 0 | 縦方向の結合 | 省略可(初期値) |
| axis | 1 | 横方向の結合 | 省略可 |
| join | outer | 外部結合 | 省略可(初期値) |
| join | inner | 内部結合 | 省略可 |
| ignore_index | True | インデックス番号の再振当 | 省略可 |
| ignore_index | False | インデックス番号の引継 | 省略可(初期値) |
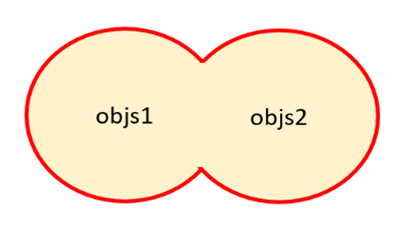
「外部結合」と「内部結合」
「外部結合」とは、結合対象となる「objs」に含まれるすべてのデータを結合することを指します。具体的には、下図のとおり2つの「objs」がある場合、赤線で囲まれた範囲のデータを結合します。
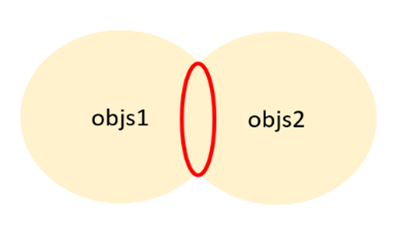
一方で、「内部結合」とは、結合対象となる「objs」に共通して含まれるデータを結合することを指します。具体的には、下図のとおり2つの「objs」がある場合、赤線で囲まれた範囲のデータを結合します。
具体的な使い方
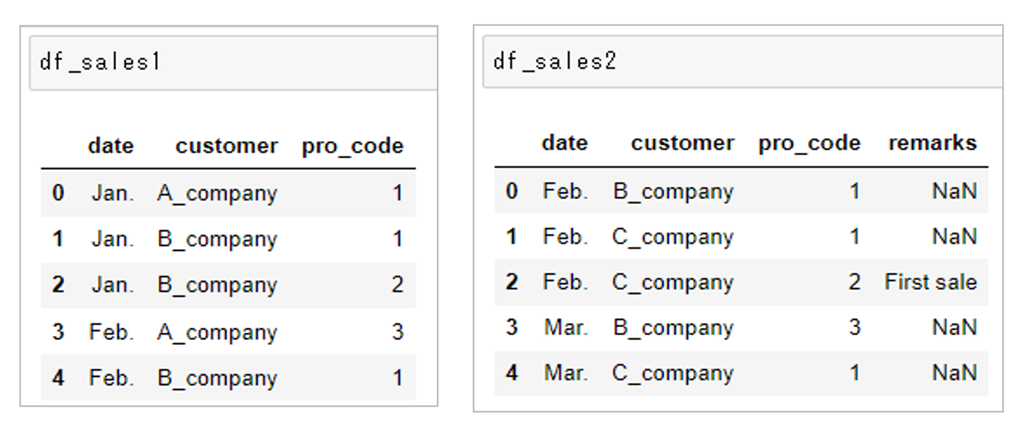
外部結合
2つの「DataFrame」である「df_sales1」と「df_sales2」を縦方向に結合します。
引数を指定しない場合は「外部結合」による結合になります。
df_sales1 = pd.read_excel("Sample_File\sales1.xlsx")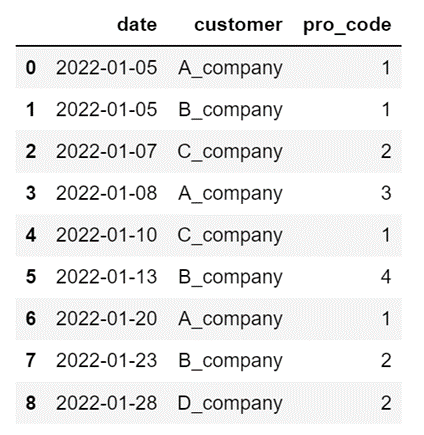
df_sales2 = pd.read_excel("Sample_File\sales2.xlsx")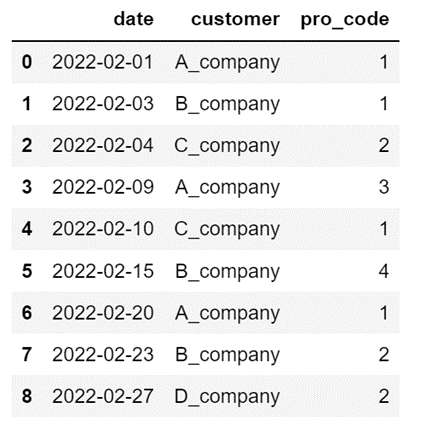
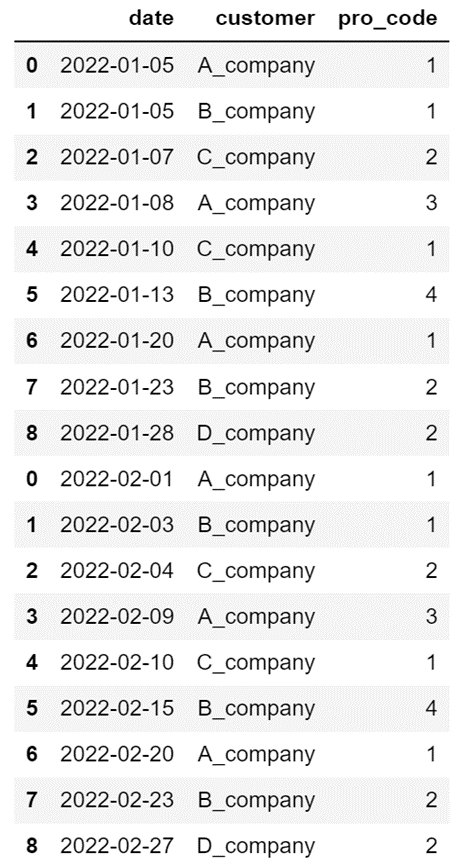
2つの「DataFrame」を結合します。
df_sales = pd.concat([df_sales1, df_sales2], axis=0)
内部結合
2つの「DataFrame」である「df_sales1」と「df_sales2」を縦方向に結合します。
引数を指定すれば「内部結合」による結合ができます。
先ほどの内容を変更して、「内部結合」による結合結果を確認します。
2つの「DataFrame」を結合します。
df_sales_join = pd.concat([df_sales1, df_sales2], join="inner")
列名「remarks」が表示されていないことが確認できます。
「concat」をもちいたデータ結合の方法について、詳しくは「【Python】「concat」によるデータの統合方法|Pandas」をご覧ください。

【横方向】データの結合|merge
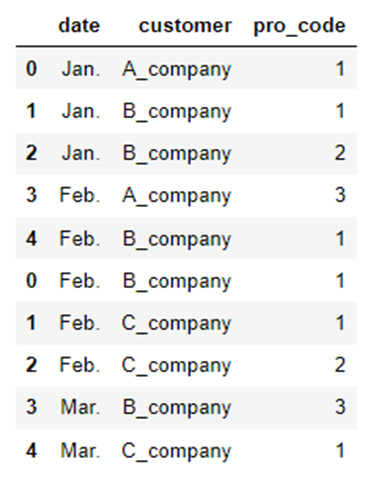
「merge」メソッドを使えば、基準となるデータに対して他のデータを関連付することができます。
例えば、以下のように2つの「DataFrame」を関連付けすることによって、共通する列名「pro_code」をもちいて双方のデータを連携することができます。
基本的な操作方法
pd.merge(left, right)基本的な引数はこちらです。
| 引数 | 値 | 結果 | 備考 |
| how | left | 「左側結合」 2つの引数うち左側の「DataFrame」を基準にデータ連携します。左側に含まれている行すべてを表示します。 | 省略可(初期値) |
| how | right | 「右側結合」 2つの引数うち右側の「DataFrame」を基準にデータ連携します。右側に含まれている行すべてを表示します。 | 省略可 |
| how | inner | 「内部結合」 結合対象に共有して含まれるデータを結合します。 | 省略可(初期値) |
| how | outer | 「外部結合」 結合対象に含まれるすべてのデータを結合します。 | 省略可 |
| on | 列名 | 「データ連結の基準列」を指定します。 (省略した場合は自動的に重複する列名での結合されます。) | 省略可 |
| left_on | 列名 | 左側の「DataFrame」から「結合の基準列」を指定します。左右で「DataFrame」の列名が異なる場合に「right_on」とあわせて使用します。 | 省略可 |
| right_on | 列名 | 右側の「DataFrame」から「結合の基準列」を指定します。左右で「DataFrame」の列名が異なる場合に「left_on」とあわせて使用します。 | 省略可 |
「左側基準」と「右側基準」
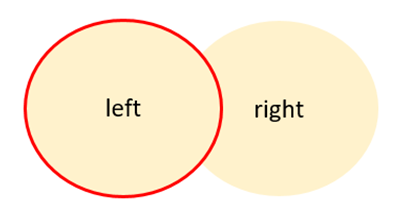
「左側基準」とは、結合対象に含まれるデータのうち、左側のデータを基準として結合することを指します。
具体的には、下図のとおり2つのデータを「左側基準」で結合した場合、左側のデータすべてが表示されますが、右側のデータはすべて表示されるのではなく、左側のデータに関連するデータのみが表示されます。
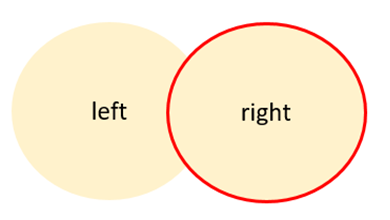
一方で、「右側基準」とは、結合対象に含まれるデータのうち、右側のデータを基準として結合することを指します。
具体的には、下図のとおり2つのデータを「右側基準」で結合した場合、右側のデータすべてが表示されますが、左側のデータはすべて表示されません。右側に関連する左側のデータのみが表示されます。
具体的な使い方
左側基準で結合|how=”left”
2つの「DataFrame」である「df_sales」と「df_products」を横方向に結合します。
引数を指定しない場合は「左側基準」による結合になります。
df_sales = pd.read_excel("Sample_Data\df_sales.xlsx")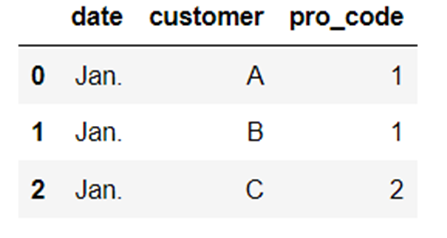
df_products = pd.read_excel("Sample_Data\products.xlsx")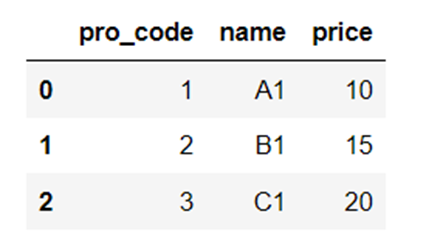
df_merge = pd.merge(df_sales, df_products)
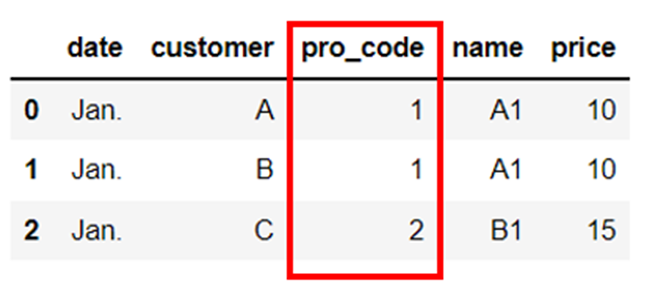
右側基準で結合|how=”right”
2つの「DataFrame」である「df_sales」と「df_products」を横方向に結合します。
引数を指定すれば「右側基準」による結合ができます。
先ほどのデフォルト値である「how=”left”」とはちがい、右側の「DataFrame」を基準として結合がされています。
そのため、右側の「DataFrame」である「df_products」すべての行が表示されるため、
左側の「DataFrame」にはない情報が「NaN(データが何もない状態のこと)」として表示される結果となっています。
df_merge_right = pd.merge(df_sales, df_products, how="right")
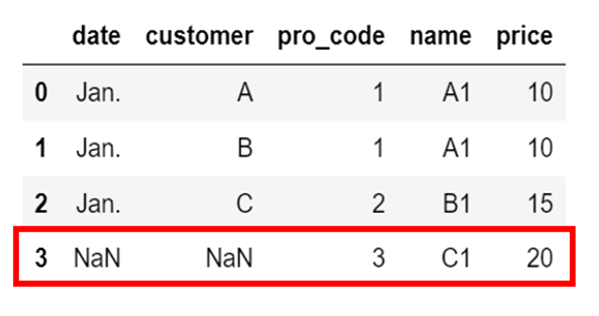
スポンサーリンク
欠損データの取扱方法
欠損データの取り扱い方法についての操作方法をご紹介します。
欠損データの確認
こちらの「DataFrame」を使って確認します。
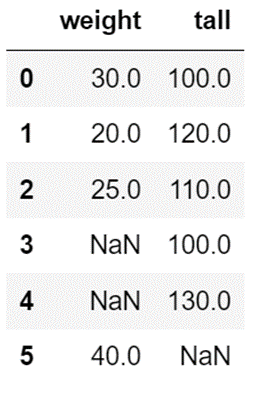
「isna」メソッドを使って、欠損データが含まれているかどうかを確認します。
(「isnull」メソッドも同じ結果を表示します。)
df.isna()

欠損データは「True」として表示されます。
欠損データの補完
欠損データを補完する方法です。
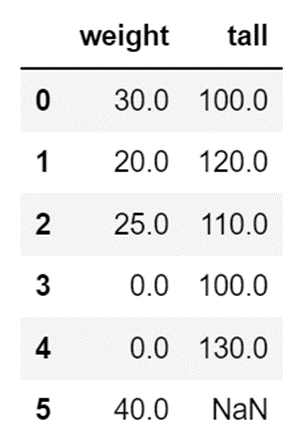
指定値で補完
欠損データを指定した値で補完します。
df["weight"] = df["weight"].fillna(0)
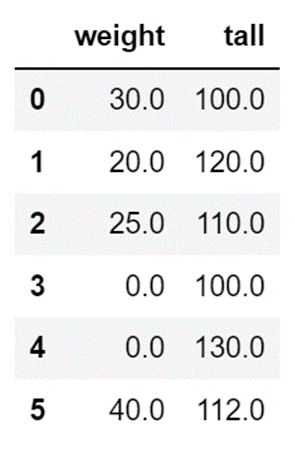
算出値で補完
欠損データを算出した値で補完します。
こちらは「平均値」をつかった補完方法です。
df["tall"] = df["tall"].fillna(df["tall"].mean())
保管方法は「平均値」以外にも、例えばこのような方法があります。
| メソッド | 内容 |
| mean | 平均値 |
| median | 中央値 |
| mode | 最頻値 |
欠損データの削除
欠損値の削除には「dropna」メソッドを使用します。
df.dropna()
基本的な引数はこちらです。
| 引数 | 値 | 説明 |
| axis | 0 | (省略可) 欠損値が含まれている行をすべて削除します。(一つでも欠損値が含まれていれば、行全体を削除します。) |
| axis | 1 | 欠損値が含まれている列をすべて削除します。(一つでも欠損値が含まれていれば、列全体を削除します。) |
| how | any | (省略可) 「行単位」で一つでも欠損値が含まれていれば、行を削除します。 「axis=1」と同時に使用することによって、「列単位」で一つでも欠損値が含まれていれば、列を削除します。 |
| how | all | 「行単位」で行すべてが欠損値であれば、行を削除します。 「axis=1」と同時に使用することによって、「列単位」で列すべてが欠損値であれば列を削除します。 |
こちらのデータをつかって欠損の削除方法をご説明します。
df = pd.read_excel("Sample_File\Sample_List.xlsx")
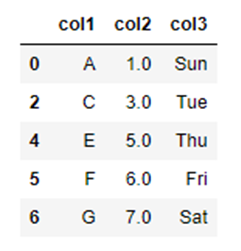
行の削除
引数の「axis」を「axis=0」とします。
df_axis_0 = df.dropna(axis=0)
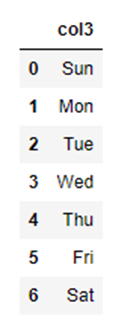
列の削除
引数の「axis」を「axis=1」とします。
df_axis_1 = df.dropna(axis=1)
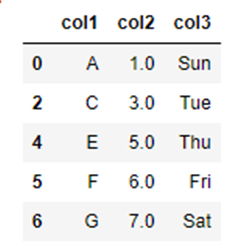
行列の削除|any
引数の「how」を「how=”any”」とすることによって、「行」もしくは「列」にひとつでも欠損値が含まれていたら削除します。
(削除対象となる「行」もしくは「列」は、引数「axis」にて指定することができます。)
df_how_any = df.dropna(how="any")
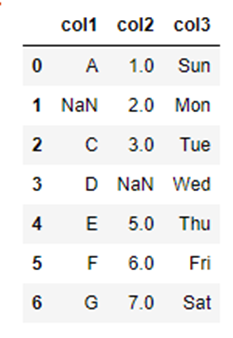
行列の削除|all
引数の「how」を「how=”all”」とすることによって、「行」もしくは「列」すべてに欠損値が含まれていたら削除します。
(削除対象となる「行」もしくは「列」は、引数「axis」にて指定することができます。)
df_how_all = df.dropna(how="all")
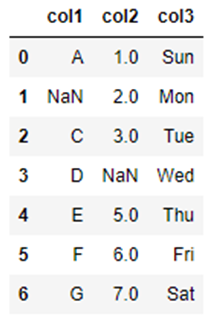
行すべてに欠損値が含まれている場合に「how=”all”」としたときの結果を確認します。
こちらのデータ変数名「df2」を使います。
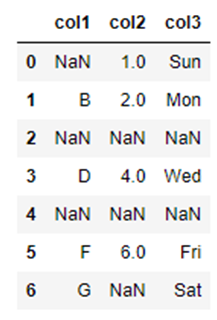
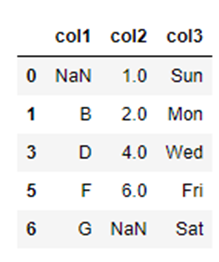
df2_how_all = df2.dropna(how="all")
こちらが実行結果です。
「行すべて」に欠損値が含まれていた行が削除されていることが確認できます。
データのグループ集計
特定の条件に一致する値を集計することができます。
「Pandas」をつかってできる集計方法を具体例をつかってご紹介します。
groupby
「groupby」は、同じ列名をもつ値を一つにまとめるためのメソッドです。「groupby」をつかって、共通させたい列名を指定します。
なお、「groupby」は以下のような関数と組み合わせて使用します。
| 関数 | 内容 |
| sum | 合計値を算出 |
| mean | 平均値を算出 |
| count | データの個数を算出 |
| std | 標準偏差を算出 |
| min | 最小値を算出 |
| max | 最大値を算出 |
こちらの「DataFrame」をつかって確認します。
df = pd.read_excel("Sample_File\sum.xlsx")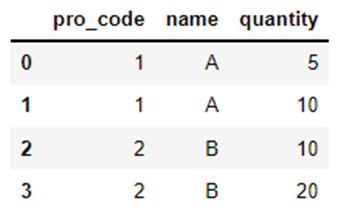
列名「pro_code」と「name」によるグループ化と合計値の算出をしています。
df_sum = df.groupby(["pro_code", "name"]).sum()

例では、リスト型をつかって2つの列名(「pro_code」と「name」)を指定していますが、「1つ」でも、「3つ以上」でも指定することができます。
pivot_table
「pivot_table」を使うことによって、さまざまな条件からデータ集計の結果を確認することができます。
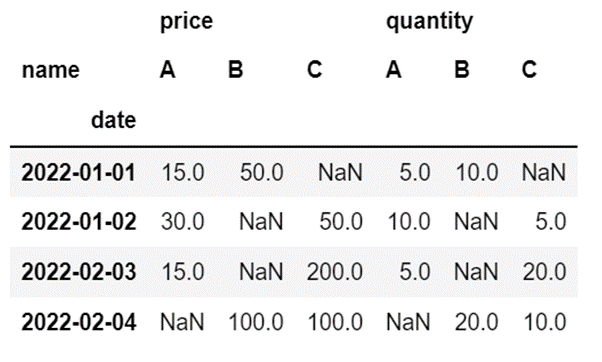
df2 = pd.read_excel("Sample_Data\sum2.xlsx")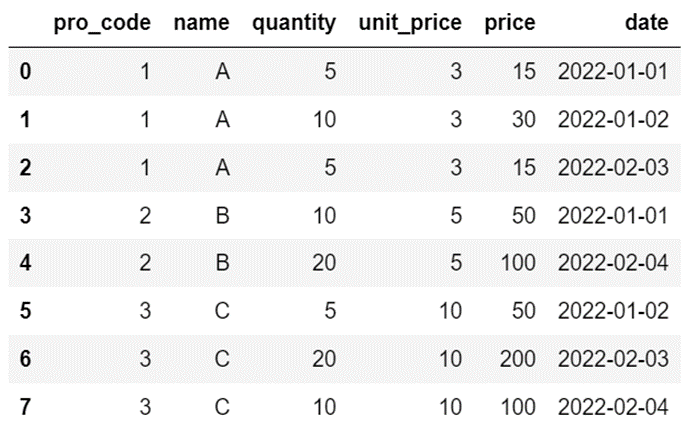
df_sum2 = pd.pivot_table(df2, index="date", columns="name", values=["quantity", "price"], aggfunc="sum")
スポンサーリンク
データのグラフ化
データをグラフを使って可視化する方法をご紹介します。
「Pandas」とは別の「サードパーティライブラリ」ではありますが、「Matplotlib」を使用します。
「Pandas」とセットでつかわれることが多いため、あわせて確認しておきましょう。
事前準備|Matplotlib
Pythonのサードパーティライブラリ「Matplotlib」をつかってデータをグラフ化することができます。より直感的にデータを分析するために、基本的な使い方を確認しておきましょう。
まずは、管理ツールの「pip」をつかってコンピューターに「Matplotlib」をインストールをします。(すでにインストールされている場合はこちらの工程は不要です。)
pip install malplotlibつぎに「サードパーティライブラリ」を使える状態にするためにモジュールを「import」します。グラフの描画には、モジュール「Matplotlib」の関数「pyplot」を使用します。
「Pandas」を「pd」と省略されることと同じように、慣習的に「pyplot」は「plt」と省略されることが一般的です。
import matplotlib.pyplot as plt
グラフの描画
「Matplotlib」をつかって描画できるグラフを具体例をつかってご紹介します。
なお、今回のグラフ化で用いるデータは以下のものを使用しています。
サンプルデータ|load_iris
データのグラフ化を確認するにあたって、サンプルデータとして別の「サードパーティライブラリ」で提供されているデータを使用します。
ちなみに、サンプルデータの提供元のライブラリ「scikit-learn(読み:サイキット ラーン)」は、機械学習に特化したライブラリです。
今回のグラフ化に用いるデータ「load_iris」は、機械学習の分類モデルのテストをおこなう際に使われる代表的なサンプルデータのひとつです。
まずは、管理ツールの「pip」をつかってコンピューターに「scikit-learn」をインストールをします。
(すでにインストールされている場合はこちらの工程は不要です。)
pip install scikit-learnつぎにデータセットを使用できるようにするために「road_iris」をインポートして、インポートした関数を変数に代入します。
from sklearn.datasets import load_iris iris = load_iris()
取得したデータの内容を確認します。
df_iris = pd.DataFrame(iris.data, columns=iris.feature_names)
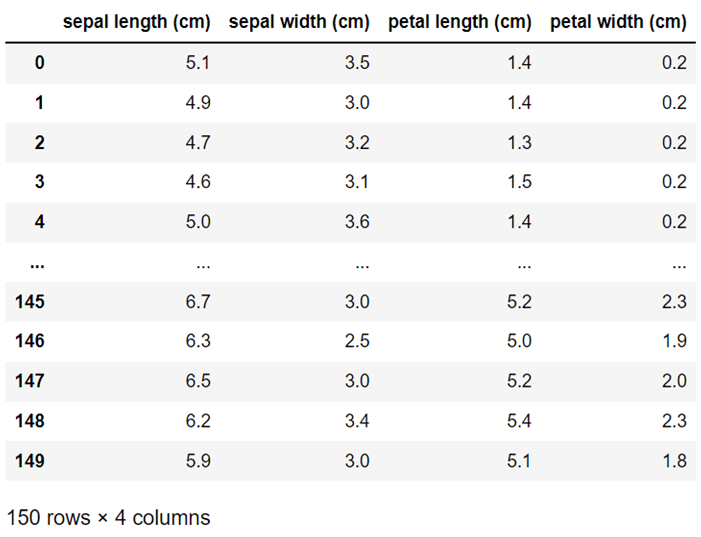
代入した変数「iris」のデータには、「150行 4列」の情報が格納されています。
それぞれの列情報は以下のとおりです。
| 列名(feature_names) | 意味 |
| sepal length | ガクの長さ |
| sepal width | ガクの幅 |
| petal length | 花弁の長さ |
| petal width | 花弁の幅 |
すでにサンプルデータがあるようでしたら、そちらを使ってご確認ください。
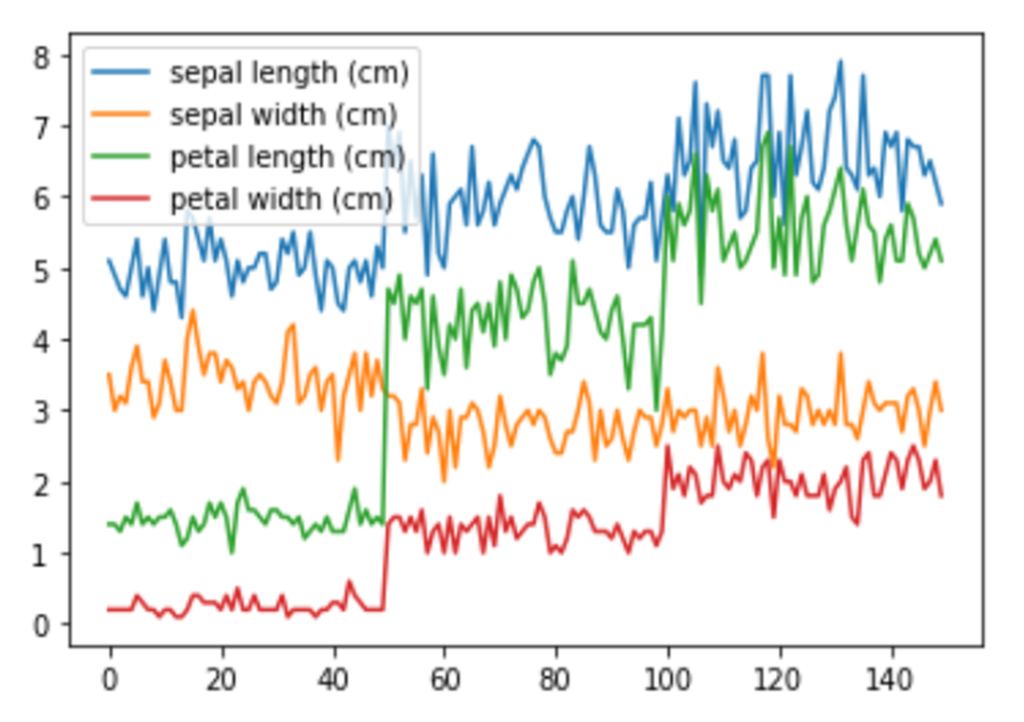
折れ線グラフ|plot()
df_iris.plot()
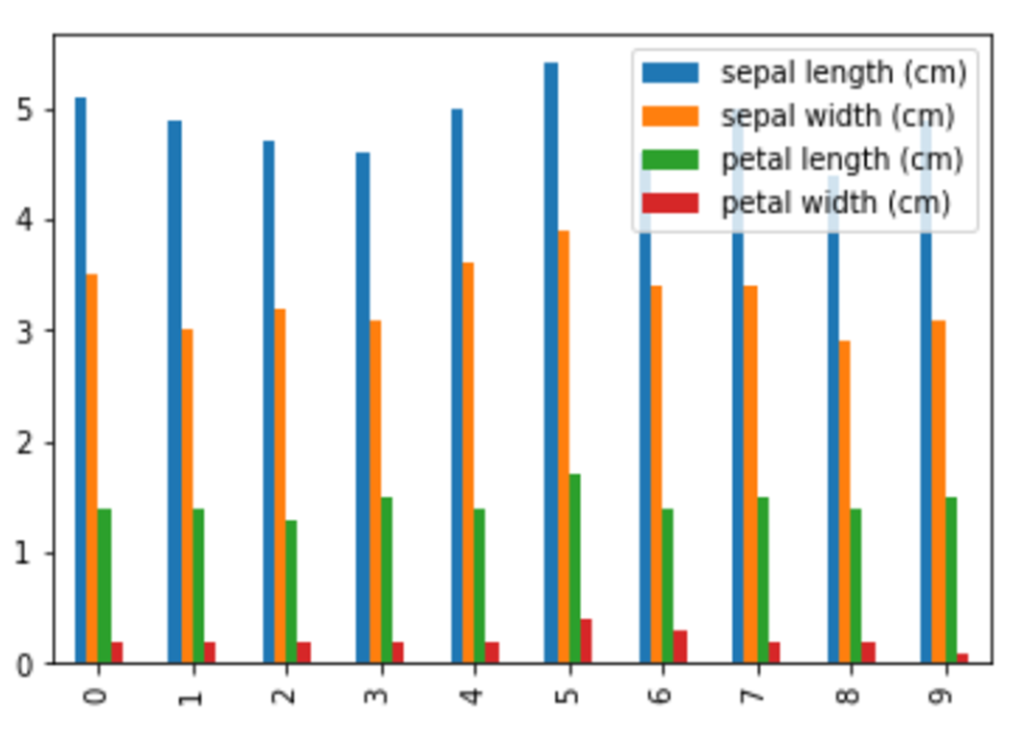
縦棒グラフ|plot(kind=”bar”)
グラフ表示の都合上、「0~9」のデータ表示に制限をしています。
df_iris[0:10].plot(kind="bar")
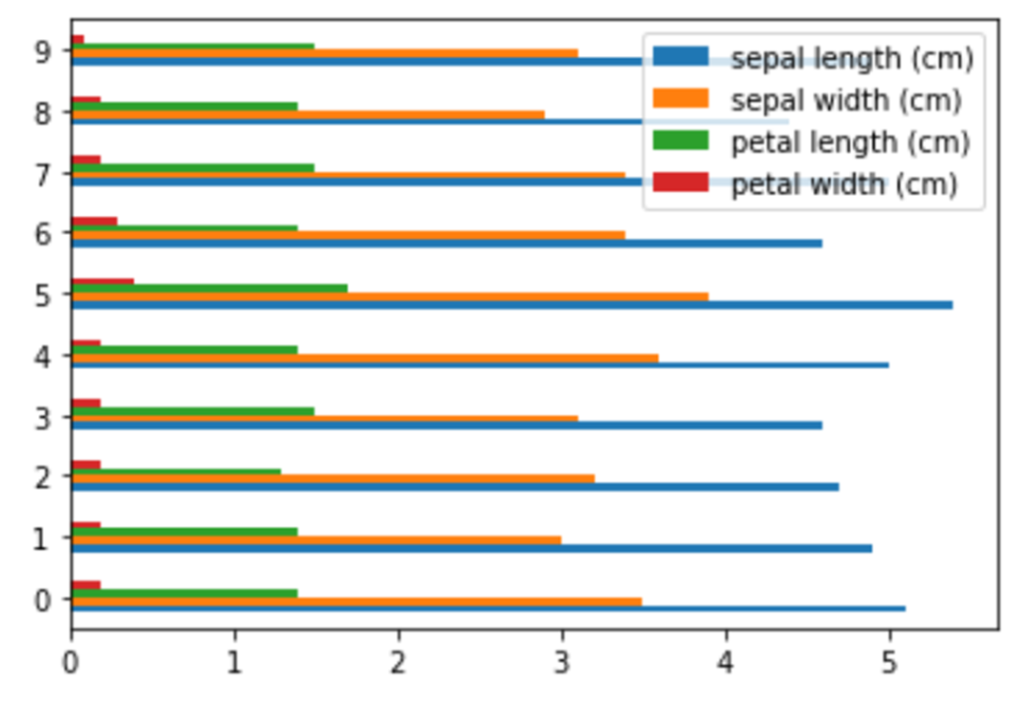
横棒グラフ|plot(kind=”barh”)
グラフ表示の都合上、「0~9」のデータ表示に制限をしています。
df_iris[0:10].plot(kind="barh")
箱ひげ図|plot(kind=”box”)
データ分布の「ばらつき具合」を確認する際に使います。
df_iris.plot(kind="box")

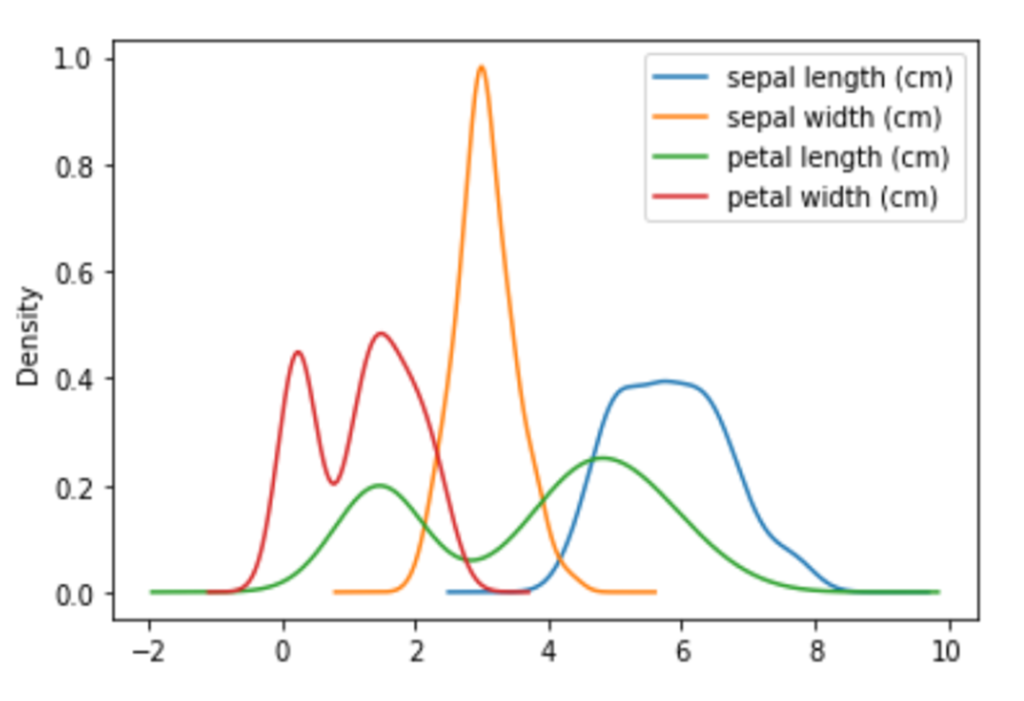
密度プロット|plot(kind=”kde”)
df_iris.plot(kind="kde")
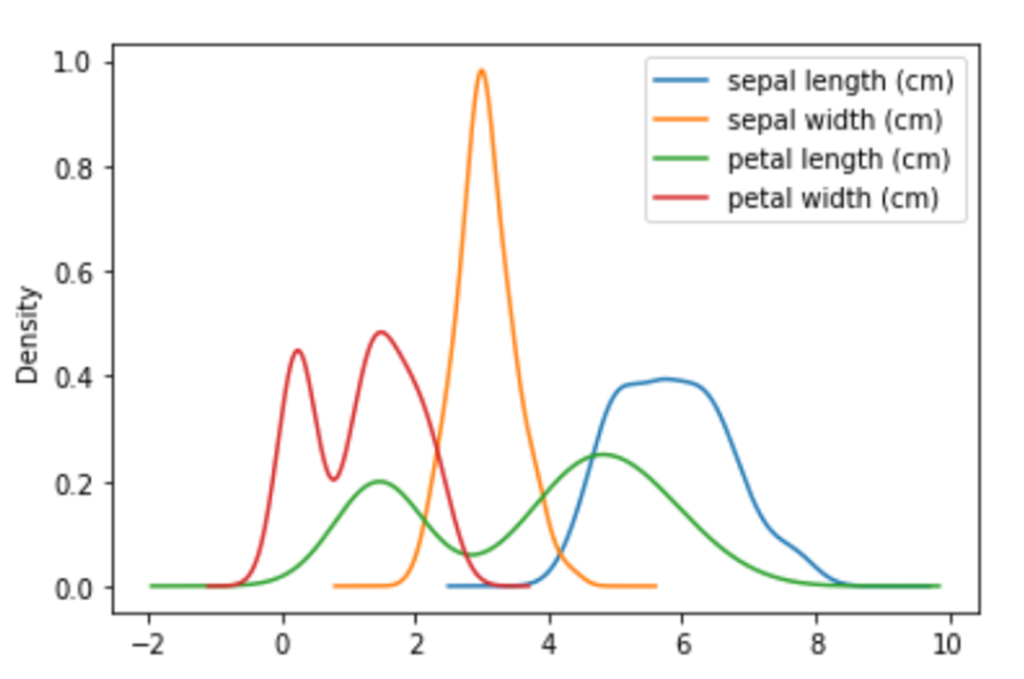
密度プロット|plot(kind=”density”)
df_iris.plot(kind="density")
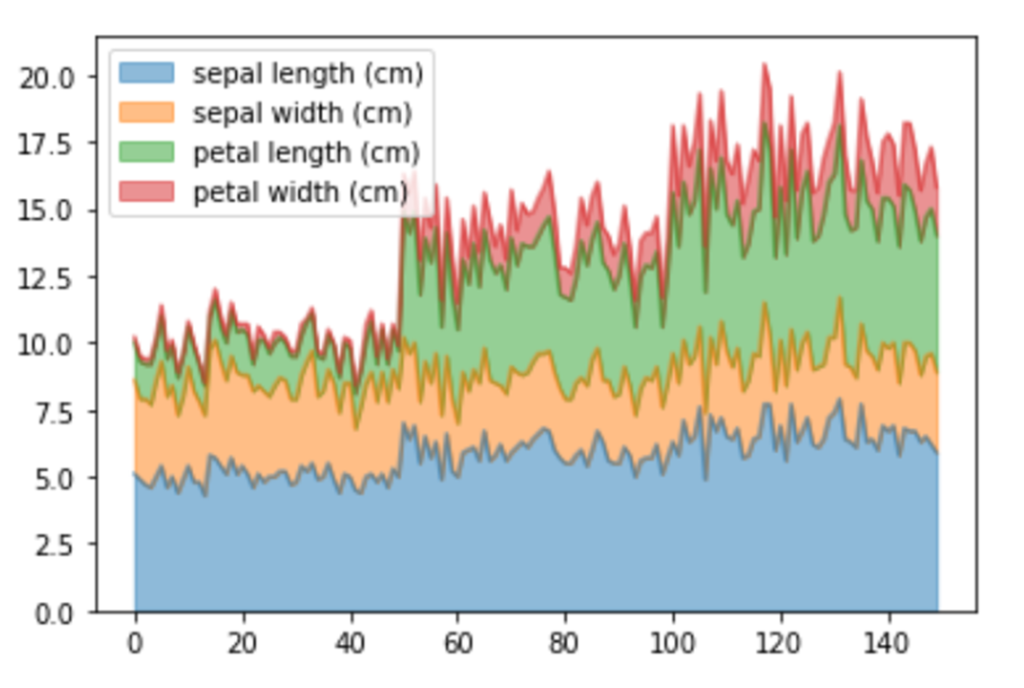
面グラフ|plot(kind=”area”)
引数「alpha」を設定することによって、グラフの透明度を指定することができます。
df_iris.plot(kind="area", alpha=0.5)
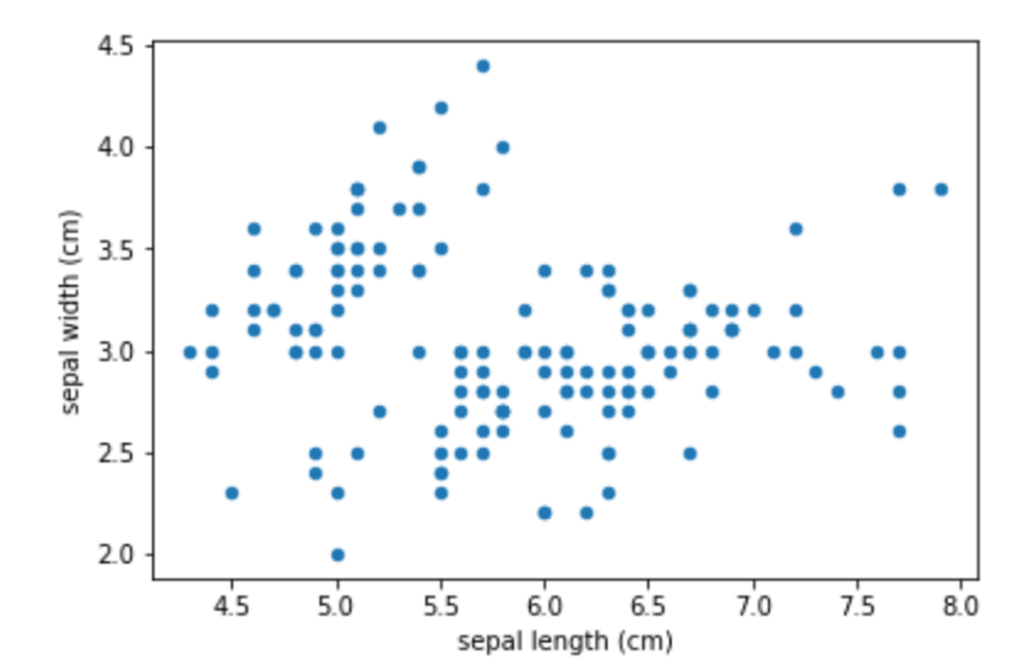
散布図|plot(kind=”scatter”)
df_iris.plot(kind="scatter", x="sepal length (cm)", y="sepal width (cm)")
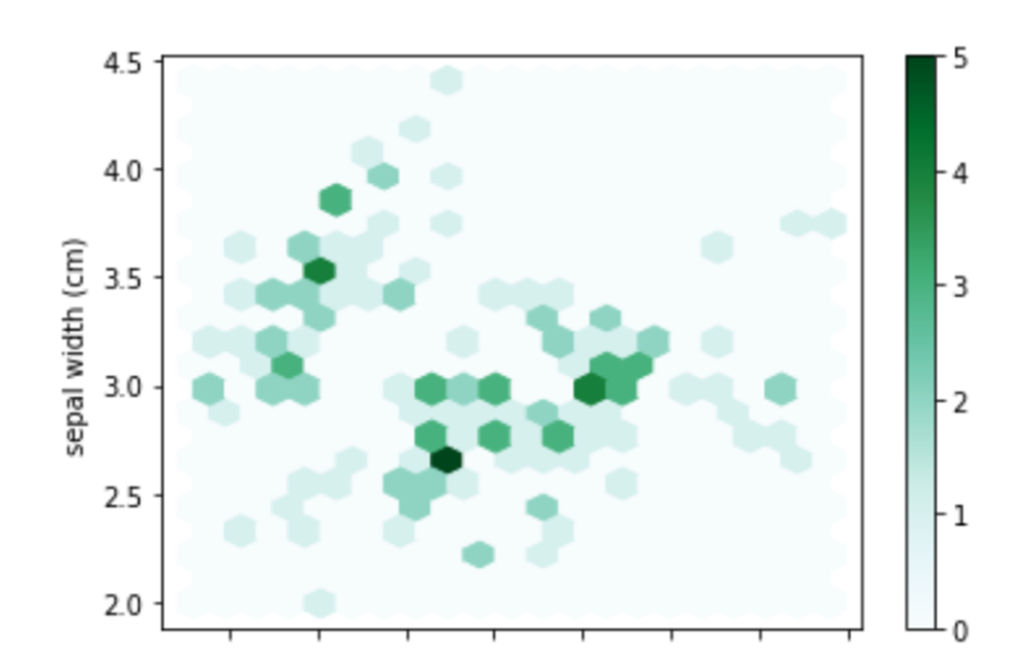
六角形ビン|plot(kind=”hexbin”)
df_iris.plot(kind="hexbin" ,x="sepal length (cm)", y="sepal width (cm)" ,gridsize=20)
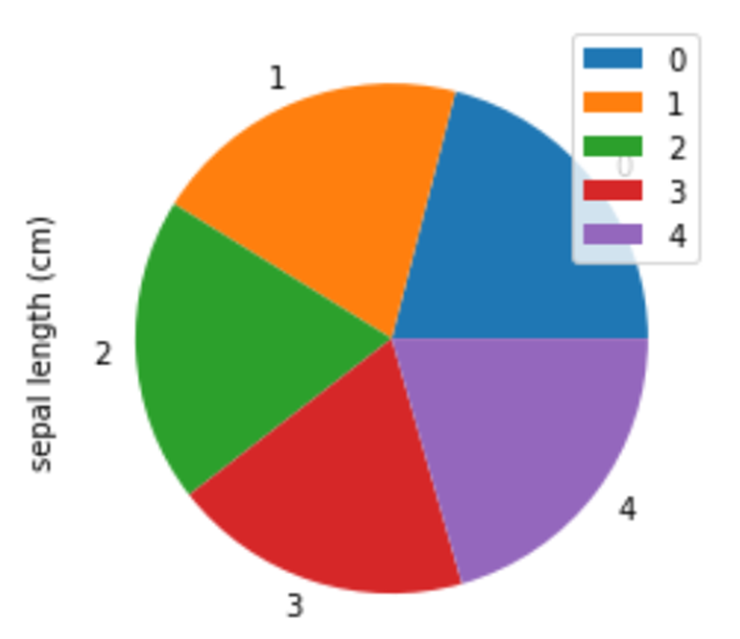
円グラフ|plot(kind=”pie”)
df_iris[0:5].plot(kind="pie", y="sepal length (cm)")