

こちらでは、PythonをつかったAI OCRの作成例をご紹介します。
今回ご紹介する内容は、PDFや画像データに含まれている文字を読み取って、文字データとして出力する機能となっています。
なお、OCRによる文字読み取りは、「GCP(Googleのクラウドサービス)」をつかっています。
こちらのサービスは、使い方によっては「有償」となる場合がありますので、あらかじめ料金体系についての内容をご確認ください。
AIをつかわない従来型のOCRと比べて、文字読み取りの精度が非常に高いと感じましたので、ぜひともお試しください。
この記事でご紹介しているポイントはこちらです。
- Pythonの実践的な活用例がわかる
- AI OCRの文字読取の精度を実際に試してみることができる
- GCP(Googleのクラウドサービス)の具体的な使い方がわかる
OCRとは
「OCR」とは「Optical Character Reader」の略称で、PDFや写真データなどのテキスト部分を認識して、文字データに変換することができる光学文字認識のことです。
これに対して「AI OCR」とは、従来のOCRにAI技術を加えたものです。
機械学習による文字認識率の向上により、手書きの文字を読み取ることも実現できるようになりました。
GCPとは
「GCP」とは「Google Cloud Platform」の略称で、Googleがクラウド上で提供しているサービスを指しています。
「GCP」は、Amazonの「AWS」やMicrosoftの「Azure」などのような、いわゆるクラウドサービスの一つです。
ちなみにクラウドサービスとは、「従来は利用者が手元のコンピューターで利用していたデータやソフトウェアを、ネットワーク経由でサービスとして利用者に提供するもの」です。
Cloud Vision
今回は、数ある「GCP」のサービスなかでも、機械学習に関連するサービスである「Cloud Vision」を使います。
「Cloud Vision」では、例えばこちらのような機能を利用することができます。
- 画像ラベリング
- 顔やランドマークの検出
- 光学式文字認識(OCR)
- 露骨な表現のあるコンテンツのタグ付け
実際に「Cloud Vision」の機能をAPIのデモをつかって試してみることができますので、まずはこちらGoogle Cloud の「Cloud Vision API」でご確認ください。
具体的な確認方法はこちらです。
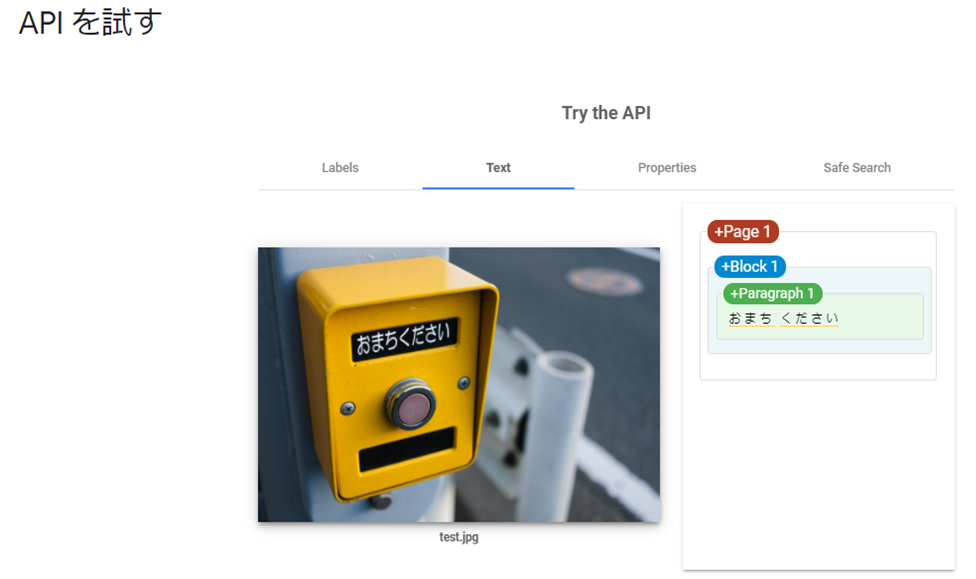
こちらでは、画像に含まれている文字「おまちください」の読み取り精度を確認しています。
1.試してみたい画像を用意

2.赤枠箇所に画像をドラッグ アンド ドロップ
3.結果を確認
料金体系
「GCP」は他社の利用料よりも低価格に設定されていますが、「従量課金制」での利用料が発生します。初期費用や解約金などは必要ありませんので、利用に応じた支払いをすることとなります。
なお、料金体系については執筆時点から変更される可能性もありますので、利用の際にはGoogleからの案内「Cloud Visionの料金」をご確認ください。
今後変更されるかもしれませんが、執筆時点では「毎月最初の 1,000 ユニットについては無料」とされています。
ここにある「ユニット」ですが、例えば、1つの画像に対して「顔検出」と「ラベル検出」の2つの機能を適用した場合、「2ユニット」としてカウントされます。
そのため、小規模な利用であれば無料枠の範囲内でつかうこともできます。
事前準備
Cloud Vision を使用するためには、「Vision API」の設定が必要です。
具体的な設定方法については、つぎの3つの手順をご覧ください。
手順1|プロジェクトを作成
Google Cloud が提供するサービスを使用するためには、プロジェクトを作成する必要があります。
具体的な手順はこちらです。
- Google Cloud Console の「請求先アカウントを管理」ページにログインします。
(補足情報に移動先のリンク情報が掲載されています。) - ページの上部にある「組織の選択」プルダウン リストで、プロジェクトを作成する組織を選択します。
(リストが表示されない場合、この手順は不要です。) - 「プロジェクトを作成」をクリックします。
- 「新しいプロジェクト」ウィンドウで、プロジェクト名を入力して該当する請求先アカウントを選択します。
- 「場所」ボックスに親組織またはフォルダを入力します。
- 「新しいプロジェクト」の詳細の入力後に「作成」をクリックします。
手順2|課金を有効にする
Google Cloud の利用料金に対する請求先のアカウントを設定します。
無料の試用期間中や、Google Cloud の無料枠内の利用であっても、請求先アカウントを設定する必要があります。
具体的な手順はこちらです。
- Google Cloud Console の [請求先アカウントを管理] ページにログインします。
- 「アカウントを作成」をクリックします。
- Cloud 請求先アカウントに関連付けられる Google お支払いプロファイルを選択します。
- オプションと詳細の設定が完了後、「送信して課金を有効にする」 をクリックします。
手順3|APIを有効にする
プロジェクトで Vision API を有効にする必要があります。
具体的な手順はこちらです。
- Cloud Console のAPI ライブラリページに移動します。
(補足情報に移動先のリンク情報が掲載されています。) - API を有効にする Cloud プロジェクトを選択します。
- 有効にする API をクリックします。
- 「有効にする」ボタンをクリックします。
スポンサーリンク
「pdf2image」と「Poppler」
今回は「pdf2image」と「Poppler」の2つをつかって、PDFを画像に変換します。
それぞれの概要は次のとおりです。
- 「pdf2image」: PDFを画像に変換するためのライブラリ
- 「Poppler」: PDFドキュメントの閲覧に用いられるフリーのプログラミング ライブラリ
「pdf2image」では、PDFを変換する際に「Poppler」を呼び出して使用します。
そのため、こちらの2つを組み合わせることによって、PDFを画像に変換することができます。
事前準備
それぞれの設定方法はこちらです。
pdf2image
「PyPI」からpipコマンドをつかって、ライブラリ「pdf2image」をインストールします。
pip install pdf2imageちなみに「PyPI」とは、「Python Package Index」の略称で、Pythonのサードライブラリのソフトウェアを保管しているデータベースのことです。
Poppler
「GitHub」から「Poppler」をダウンロードします。
- 「GitHub」からZIPファイルをダウンロードします。
- ダウンロードしたファイルを展開します。
- 任意の場所にフォルダーを保存します。
(後ほどPythonコードから環境変数を指定します。)
「GitHub」は、ソフトウェアの開発のためのプラットフォームです。
「GitHub」 を使えば、開発者同士でデータを共有するだけでなく、プロジェクトの管理をしながらソフトウェアの開発もおこなうことができます。
Python|コードの紹介
こちらでは今回お伝えするコードについての内容をまとめています。
フォルダーの構成
こちらで使用するフォルダーの構成はつぎのとおりです。
| フォルダー名 | 内容 |
| Before_Extraction | 読み取り対象となるファイルを格納しているフォルダーです。 |
| Convert_Files | フォルダー「Before_Extraction」の子フォルダです。 |
| After_Extraction | 画像ファイルから抽出した文字情報を「テキスト形式」に変換したものを保存するためのフォルダーです。 |
コードの動作
おおまかなコードの動作の流れはつぎのとおりです。
1.PDFを画像ファイルに形式変換する
「Vision API」の読み取り対象が、PDFではなく画像ファイルとなっているため、ファイル形式を変換します。
2.読取対象のファイルをフォルダー「Convert_Files」にまとめてコピー
フォルダー「Before_Extraction」に「PDFファイル」が含まれている場合、画像ファイルに変換したものをこちらのフォルダーに保存します。
また、フォルダー「Before_Extraction」に「画像ファイル」が含まれている場合、コピーを作成してこちらのフォルダーに保存します。
こちらでは、ファイル形式の変更前後を区別するために新しいフォルダーを設けています。
今回ご紹介する例では実装していませんが、PDFから画像にファイル変換をおこなったデータが不要であれば、さいごに対象のフォルダーを削除していただいても良いかと思います。
3.画像ファイルから抽出した文字情報の保存
フォルダー「Convert_Files」のファイルを「Vision API」で読み取って、文字情報を抽出します。
こちらで抽出された文字情報をテキスト形式にして、フォルダー「After_Extraction」に保存します。
コードの記述
こちらでは具体的なPythonのコードをご紹介します。
事前準備
必要なモジュールをインストール
import requests import base64 import json import glob import os from pathlib import Path import re from pdf2image import convert_from_path import shutil
もしライブラリがなければ、「PyPI」からpipコマンドをつかって、さくっとインストールをしましょう。
変数の定義
「●●●」の箇所には、ご紹介した手順で取得した「API KEY」を入力します。
また、「★★★」の箇所には、作成する各フォルダーにあわせて記述をしてください。
GOOGLE_CLOUD_VISION_API_URL = "https://vision.googleapis.com/v1/images:annotate?key=" API_KEY = "●●●" before_extraction_folder = r"★★★\Before_Extraction\Convert_Files" before_extraction_files = glob.glob(r"★★★\Before_Extraction\*") after_text_extraction_folder = r"★★★\After_Extraction"
関数の定義
それぞれの関数を定義します。
APIを呼び出してjson型で結果を取得
def request_cloud_vison_api(image_base64):
api_url = GOOGLE_CLOUD_VISION_API_URL + API_KEY
req_body = json.dumps({
'requests': [{
'image': {
'content': image_base64.decode('utf-8') # json変換のためにstring型に変換
},
'features': [{
'type': 'DOCUMENT_TEXT_DETECTION', # 分析内容の指定
'maxResults': 10,
}]
}]
})
res = requests.post(api_url, data=req_body)
return res.json()
画像の読込
def img_to_base64(filepath):
with open(filepath, "rb") as img:
img_byte = img.read()
return base64.b64encode(img_byte)
PDFを画像に変換
「▲▲▲」の箇所には、ご紹介した手順でインストールした「Poppler」の保存場所を指定します。例えば、「C:\Program Files\poppler-21.03.0」のような内容となります。
また、「★★★ 」の箇所には、フォルダー「Convert_Files」にあわせるように記述をします。
def format_conversion(files):
# 1.poppler/binを環境変数PATHに追加する
poppler_dir = r"▲▲▲\Library\bin"
os.environ["PATH"] += os.pathsep + str(poppler_dir)
# 2.関連ファイルのパス
image_dir = Path(r"★★★\Before_Extraction\Convert_Files")
# 3.PDFファイルの抽出
pattern_pdf = "pdf$"
for file in files:
result_pdf = re.search(pattern_pdf, file,re.IGNORECASE) # 拡張子が"PDF"(大文字、小文字の区別なし)
if result_pdf:
pages = convert_from_path(str(file), 200) # PDF -> Image に変換(200dpi)
for i,page in enumerate(pages):
file_name = os.path.basename(file) + "_{:02d}".format(i + 1) + ".png"
image_path = image_dir / file_name
save_page = page.save(str(image_path), "PNG") # PNGで保存
print(str(image_path) + " に変換ファイルを保存中です。")
return save_page
画像のコピー
def copy_files(files):
pattern_img = "jpeg$|jpg$|png$" # 画像ファイルの拡張子を指定
for file in files:
result_img = re.search(pattern_img, file, re.IGNORECASE)
if result_img:
print("ファイルのコピー: " + str(file))
return shutil.copy(file, before_extraction_folder)
ファイルの変換とテキスト保存
def convert_save():
# 読込フォルダーの指定
files = glob.glob(before_extraction_folder + "\*")
for file in files:
img_base64 = img_to_base64(file)
result = request_cloud_vison_api(img_base64)
result_text = result["responses"][0]["fullTextAnnotation"]["text"]
print("----FILE----")
print(os.path.basename(file))
print("----TEXT----")
print(result_text)
# OCR文字データをテキストファイルに保存
file_name = os.path.splitext(os.path.basename(file))[0] # 拡張子なしのファイル名
path = os.path.join(after_text_extraction_folder, file_name + ".txt")
with open(path, "w") as f:
f.write(result_text)コードの実行
さいごに実行用のコードを記述します。
format_conversion(before_extraction_files) copy_files(before_extraction_files) convert_save()
まとめ
クラウドサービスのひとつである「Google Cloud」のAPIをつかったPythonの実例をご紹介いたしましたが、いかがでしたでしょうか。
もちろん今回お伝えした内容以外にも「Cloud Vision」には多くの活用方法がありますので、もし役に立ちそうなものがあれば色々と試していただくのも良いかと思います。
わたし自身まだまだ勉強中の分野とのこともあり、長々とご説明をいたしましたが、さいごまでご覧いただきありがとうございます。
こちらの記事が少しでもお役に立てれば大変うれしく思います。

