

Pythonのライブラリのひとつ「Selenium」による要素の取得方法についてご説明をします。「Selenium」をもちいて要素を取得するためには「HTML」の基礎知識が必要ですので、まずは基本的な内容を理解しておきましょう。
HTMLがはじめてであれば次のような効果が期待できます。
- HTMLの構成が理解できるようになる
- HTMLの基本的なタグや属性を知ることができる
- WebページのHTMLの見方がわかるようになる
- WebページからSeleniumで特定の要素を取得できるようになる
HTMLとは
HTMLとは「Hyper Text Markup Language」の略称で、Webページを作成するための言語のことです。HTMLでは「タグ」と呼ばれる記号(「<(小なり)」と「>(大なり)」)をつかって文字列を囲むことによって、文章の構造を指示します。
基本的には、「開始タグ」と「終了タグ」で内容を囲むかたちで記述します。
「開始タグ」は、記号「<>」をつかってタグ名を囲みます。
また、「終了タグ」は、記号「</>」をつかってタグ名を囲みます。
具体的にはつぎのような構成となります。
<タグ名>内容</タグ名>
これらをまとめて「要素」と呼びます。
HTMLの表示例
かんたんな例をつかって実際にWebブラウザで使用されているHTMLをご紹介します。
例えば、こちらのHTMLはWebブラウザではこのように表示されます。
ちなみにファイル名を「sample.html」としています。
<!doctype html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta content="sample" name="サンプル用">
<title>サンプルHTML</title>
</head>
<body>
<h1>1番目に大きな見出しを入力</h1>
<h2>2番目に大きな見出しを入力</h2>
<p>ここで段落を表示させます</p>
<p>もうひとつ段落を表示させます</p>
<h2>2番目に大きな見出しを入力</h2>
<p>ここにも段落を表示させます</p>
<a href="https://www.google.com/">これはGoogleです</a>
</body>
</html>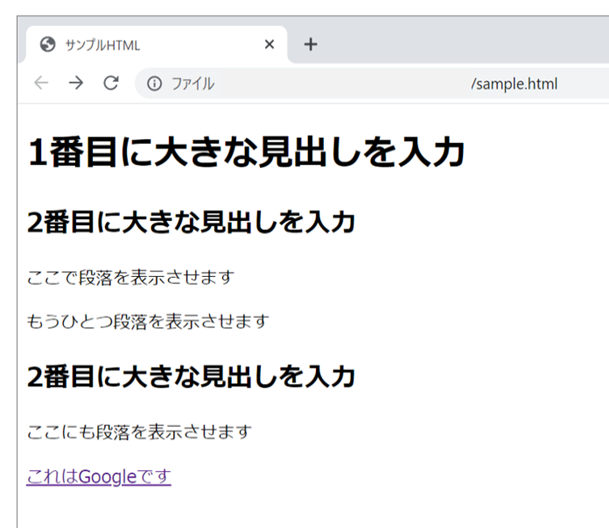
例外こそありますが、基本的には開始タグと終了タグで「内容」が囲まれていることをご理解いただければOKです。
HTMLのタグ
以下、こちらの例で使用されている「タグ」についてご紹介します。
<!doctype html>
DOCTYPE宣言と呼ばれるもので、文書が「HTML5」で作成されていることを宣言するために使用されるタグです。
「HTML5」とは、HTMLのバージョンのひとつですが、2021年1月に「HTML5」から「HTML Living Standard」へと呼称が変更されています。呼称の変更にともないHTMLの標準仕様が変更されていますが、基本的なコードの書き方でおおきな変更点はありません。
<html> </html>
「html」文書であることを宣言するためのタグです。
「開始タグ」のなかに含まれている「lang=”ja”」という部分で「属性」を指定しています。「属性」とは、開始タグのなかに記述できる付加情報のことです。タグ名のあとにスペースを入れてから内容を記述します。
この「属性」の部分で「lang = “ja”」とすることによって、言語を日本語(Japanese)に指定しています。
「属性」については後ほどご説明します。
<head> </head>
ページのタイトルや説明文などのページ情報を記述するためのタグです。
この部分はページには表示されません。
<meta>
ページ情報を検索エンジンやWebブラウザに伝えるためのタグです。
「meta charset=”UTF-8″」の部分で、文書のエンコーディングを「UTF-8」に指定しています。「UTF-8」とは最も一般的につかわれる文字コードです。
また、「meta content=”sample” name=”サンプル用”」の部分で、「content」と「name」を指定してページの説明をしています。「content」では、検索エンジンで検索をした際にページタイトルの下に表示される補足説明の文字を指定して、「name」で要素の名前を指定しています。
<title> </title>
Webブラウザのページタブや検索結果のタイトルなどに表示される名前を指定します。
こちらの例では、Webページのタブに「サンプルHTML」と表示されていることが確認できます。
<body> </body>
実際にWebブラウザに表示される文書の部分です。
<h1> </h1>
見出しを指定するためのタグです。
「h1」から「h6」までの種類があり、数字が大きくなるほど文字サイズが小さくなります。
<p> </p>
文書の段落を表示させるためのタグです。
<a> </a>
リンクを設定するテキストを指定するためのタグです。
「href属性」という「属性」をつかってリンク先を指定します。
こちらの例では、URLを”https://www.google.com/”と指定することによってGoogleのページをリンク先としています。
<div> </div>
各コンテンツをグループとしてまとめるためのタグです。
HTMLの構成をわかりやすく区切るために使用されています。
<ul> </ul>
箇条書きのリストを表示するためのタグです。
「Unordered List」を省略して表記しています。
リストの各項目は「li」タグをつかって記述されています。
<ol> </ol>
番号つきのリストを表示するためのタグです。
「Ordered List」を省略して表記しています。
リストの各項目は「li」タグをつかって記述されています。
HTMLの属性とは
属性とは、HTMLの要素に対して補足情報を設定するために使うものです。
属性は開始タグの要素名のあとに記述をします。
例えば、「aタグ」に対して「href属性」を設定するさいの書き方は次のとおりです。
<a href=”https://www.google.com”>Googleのリンク設定</a>
先ほどの例と同様、こちらの記述でWebページに表示される文字「Googleのリンク設定」の部分をクリックして別ページにジャンプさせることができる状態になります。
属性の書き方のポイントはこちらです。
- 「開始タグ(a)」のあとに「半角スペース」をはさんで「属性(href)」を記述
- 「属性(href)」のあとに「=」を記述
- 「=」のあとに「””(ダブルクォーテーション)」で
「属性値(https://www.google.com)」をはさんで記述
代表的な属性
上記では「href属性」を例にご説明をいたしましたが、その他にもさまざまな属性があります。
以下、もっとも基本的な属性をご紹介します。
href属性
href属性とは、おもにaタグのなかで用いられるハイパーリンクを設定するための属性です。
ちなみに、「href」とは「hypertext reference」の略称です。
id属性
id属性とは、要素に名前を設定するための属性で、同じページ内では同じIDが使えないといった決まりがあります。
そのため、「特定のひとつの要素」を指定する場合に使用されます。
class属性
class属性とは、要素に名前を設定するための属性で、同じページ内で何度も同一のクラスを使用することができます。
そのため、「特定のひとまとまりの要素」を指定する場合に使用されます。
src属性
src属性とは、画像やスクリプトなどを埋め込む目的で、URLを指定するための属性です。
「<img src=”URL”>画像名」のような形で「imgタグ」と一緒に使われます。
(「imgタグ」には終了タグを使いません)
ちなみに、「src」とは「source」の略称です。
HTMLについての事前説明が長くなりましたが、以降は「Selenium」についてのご説明をします。
HTMLの確認方法
Google Chromeでできる実際のWebページで使われているHTMLの確認方法をご紹介します。
手順1|検証ツールを開く
以下のいずれかの方法で「検証ツール」を開くことによってHTMLを確認することができます。
- Webページを開いた状態で「F12」を押下
- Webページ内で右クリックをして「検証」をクリック
以下のように「検証ツール」が開いて画面内にHTMLが表示されます。
手順2|Webページの要素を探す
つぎに赤枠の部分をクリックします。
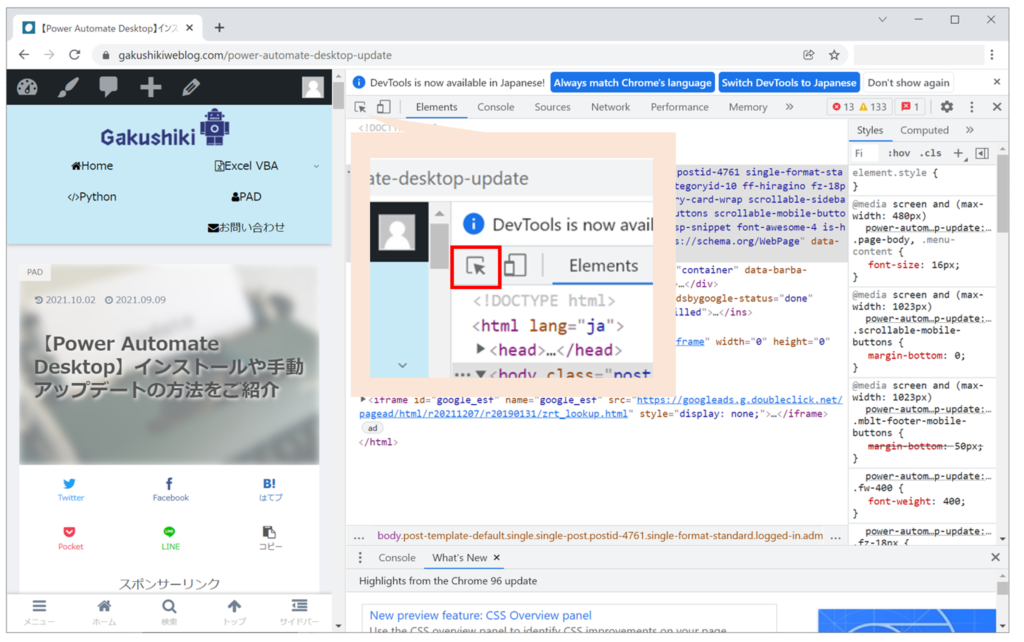
Webページ内でHTMLを確認したい箇所にマウスを移動させます。
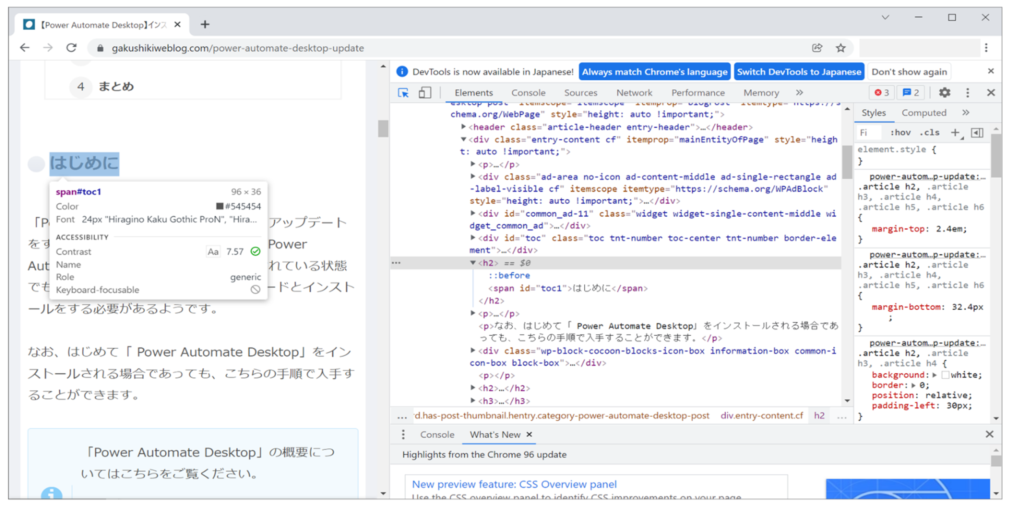
手順3|HTMLの詳細を確認する
マウスの移動先をクリックします。
Webページで選択した箇所のHTMLが選択されていることが確認できます。
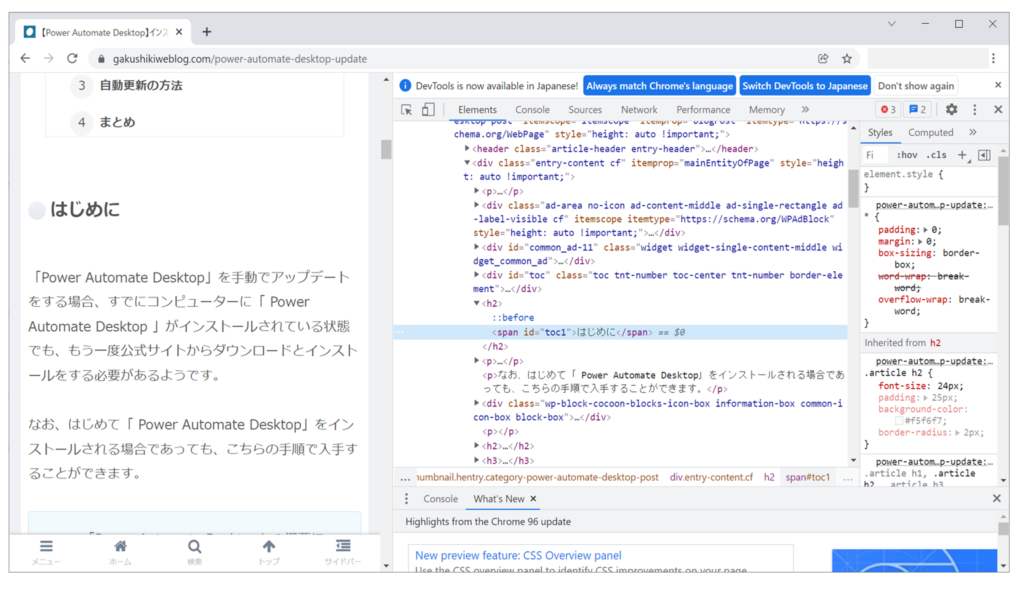
手順4|HTMLを取得する
HTMLの選択箇所で右クリックをして「Copy」を選択します。
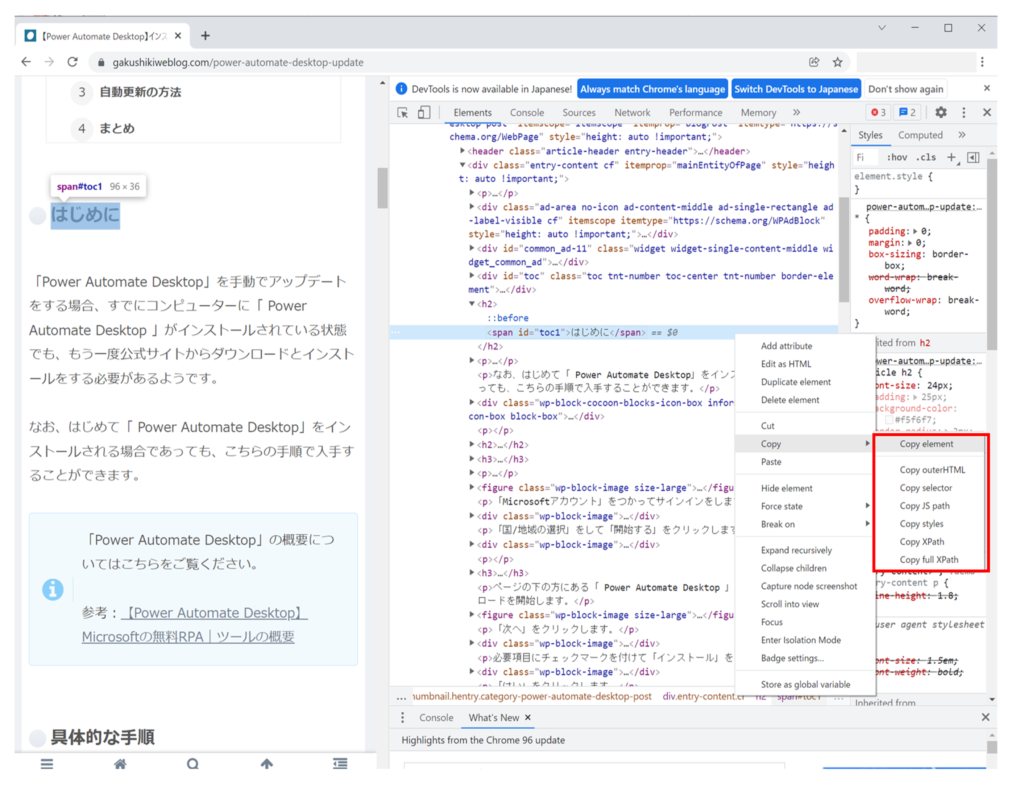
いくつかコピーの方法が出てきますが、「Copy element」を選択することによってこのような形でHTMLを取得することができます。
<span id="toc1">はじめに</span>
Seleniumとは
Seleniumとは、WEB操作を自動化するためのライブラリです。
Seleniumをうまく使えば、キーボード入力やマウス操作などによる「WEBブラウザでのいつもの操作」を自動化することができます。

こちらでは、Seleniumをつかった基本的な一連の流れについてまとめていますので、もしあまりご存じでなければイメージをつかむためにもご一読ください。
Seleniumによる要素の指定
Seleniumでは8種類の方法で要素を指定することができます。
| 取得対象 | 取得方法 | 概要 |
| tag name | find_element_by_tag_name() | ・タグ名で要素を検索する場合に使用(例:「h1」「p」「div」) ・指定されたタグ名を持つ最初の要素を取得 |
| id 属性 | find_element_by_id() | ・id属性で要素を検索する場合に使用 ・ひとつのHTMLファイルにidの重複使用は不可 |
| Class 属性 | find_element_by_class_name() | ・クラス属性で要素を検索する場合に使用 ・一致するクラス属性を持つ最初の要素を取得 |
| Name 属性 | find_element_by_name() | ・Name属性で要素を検索する場合に使用 |
| aタグ | find_element_by_link_text() | ・aタグ内で使用されているリンクテキストがわかる場合に使用 |
| aタグ | find_element_by_partial_link_text() | ・aタグ内で使用されているリンクテキストがわかる場合に使用 |
| CSS selector | find_element_by_css_selector() | ・一致するクラス属性を持つ最初の要素を取得 ・一致するCSS selectorを持つ最初の要素を取得 |
| XPath | find_element_by_xpath() | ・id属性やName属性がない場合に使用 ・XPath (XML Path Language)とは、ツリー構造となっているXML/HTMLドキュメントからの要素や属性値などを指定するための簡潔な構文(言語) ・XPathでは「 “/”(スラッシュ)」 で区切りながら階層を記述して基準となるノードから別のノードを指定 |
以下、Seleniumをつかった基本的な要素の取得方法についてご紹介をします。
事前準備
「【Python】SeleniumをつかったWEB操作の自動化」を参考にして、Webブラウザを操作するための準備をします。
まずは外部ライブラリをインポートします。
from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager from time import sleep
つぎに「WebdriverManager」を設定します。
browser = webdriver.Chrome(ChromeDriverManager().install())
そして「implicitly_wait」を設定します。
browser.implicitly_wait(10)
さいごに任意のURLを指定します。
今回は「Yahoo!ニュース」をつかいます。
url = "https://news.yahoo.co.jp/" browser.get(url)
要素の取得
事前準備が整いましたので、具体的な要素の取得方法についてご紹介をします。
「tag name」による要素の取得
タグ名「h2」つかって要素を取得します。
elem_tag_name = browser.find_element_by_tag_name("h2")「.text」をつかって取得要素を確認します。
print(elem_tag_name.text)
出力結果はこちらです。
要素が取得できていることがわかります。
トピックス「tag name」による複数要素の取得
今度は、タグ名「h2」をつかって複数の要素を取得します。
取得方法としては、先ほどの例の「element」の部分を「elements」に変更するだけで問題ありません。
elem_tag_names = browser.find_elements_by_tag_name("h2")リスト型で取得されているため、For文をつかって各要素を確認します。
for i in elem_tag_names:
print(i.text)結果はこちらです。
複数の要素を取得できていることがわかります。
トピックス
Yahoo!ニュース ライブ
あなたにおすすめ
アクセスランキング
コメントランキング
動画アクセスランキング
雑誌アクセスランキング「id属性」による要素の取得
id属性をつかって要素を取得します。
elem_id = browser.find_element_by_id("yjnHeader")
print(elem_id.text)結果はこちらです。
Yahoo!ニュース
指紋・顔認証を使ってパソコンに簡単ログイン
Yahoo! JAPAN ヘルプ
検索
IDでもっと便利に新規取得
ログインまもなく終了、条件を満たすと最大34.5%
マイページ
購入履歴
トップ
速報
ライブ
個人
オリジナル
みんなの意見
ランキング
有料
主要
国内
国際
経済
エンタメ
スポーツ
IT
科学
ライフ
地域
トピックス一覧「CSS selector」による要素の取得
CSS selectorとは、CSSによるWebページの装飾をするさいに用いられる要素の指定方法です。
以下、CSS selectorをつかって要素を取得します。
elem_css_selector = browser.find_element_by_css_selector(".sc-jGFFOr")
print(elem_css_selector.text)
結果はこちらです。
首相 NPT会議への出席見送りへ
大雪でトレーラー立ち往生 滋賀
日米 対ランサムウェアで連携へ
LGBT差別禁止 企業8割が明文化
英女王 愛する人なきXmasつらい
受験生へ 感染対策ポイント3つ
戦力外追ったD 泣きながら編集
草なぎ「吉沢亮くんに感謝」
もっと見る
全カテゴリのトピックス一覧CSS selectorの基本的な使い方はこちらです。
| 対象 | 概要 |
| tag name | 指定したタグ名を対象とします。 例えば「p」「div」「h1」などのタグ名を指定します。 |
| Class属性 | 「.(記号:ドット)」+「クラス名」で指定します。 例えば、クラス名が「test」のものを指定する場合は「.test」と記述します。 |
| id属性 | 「#(記号:ハッシュ)」+「id名」で指定します。 例えば、id名が「sample」のものを指定する場合は「#sample」と記述します。 |
| 指定要素内の要素 (子要素) | 2つのセレクタを半角スペースをはさんで指定します。 例えば、「divタグ」のなかの「pタグ」を指定したい場合、「div p」と記述します。 |
| *(記号:アスタリスク) | すべての要素を対象とします。 |
上記のほかにも取得できる方法がありますので、もし使えそうな場合は詳細をお調べいただくことをオススメします。
XPathによる要素の取得
XPathとは、Webページから要素を指定するために使われる構文です。
WebページのHTMLはツリー構造をしているため、特定の要素をXPathをつかって直接指定することによって要素を取得します。
以下、XPathをつかって要素を取得します。
elem_xpath = browser.find_element_by_xpath('//*[@id="uamods-topics"]/div/div/div/ul/li[1]/a')
print(elem_xpath.text)
結果はこちらです。
新変異株のクラスター発生 大阪
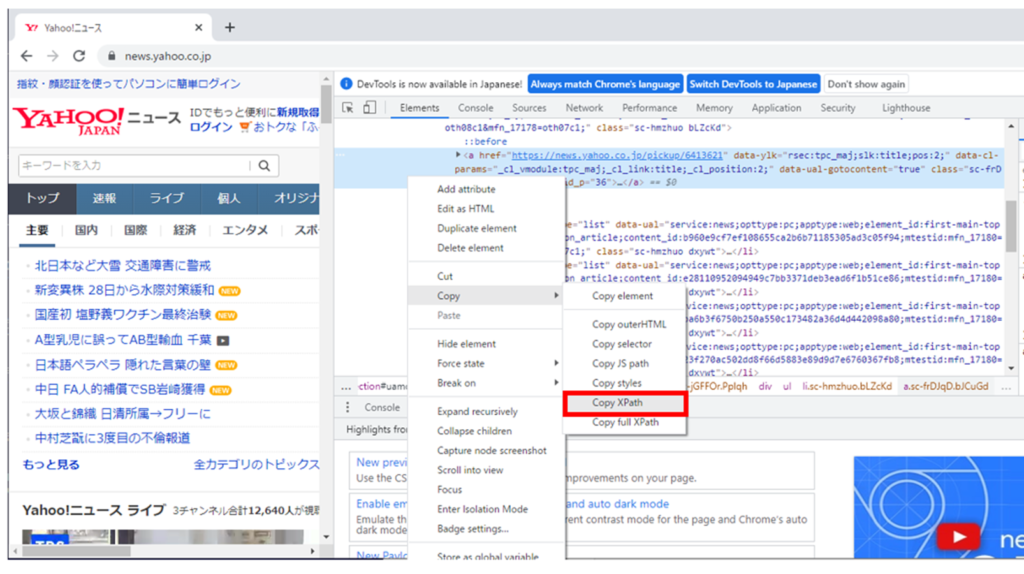
XPathの取得方法はつぎの通りです。
- 検証ツールを開く
- 取得したいHTMLの場所で右クリックをする
- 「Copy」→「Copy XPath」を選択する
XPathをつかえば細かな条件を指定して要素を取得することができます。こちらでは詳細説明を割愛していますが、正確性を重視したい場合などは、一度お調べいただくことをオススメします。
まとめ
今回はSeleniumをつかったHTMLの要素の取得方法についてご紹介をいたしました。
HTMLについての基礎知識が必要となりますが、Webページから情報を取得することができるようになれば、「できることの幅」が広がると思いますので、ぜひ一度お試しください。

