

Pythonで有名なサードパーティーライブラリーのひとつ「BeautifulSoup」と「Requests」をつかったWebスクレイピングの方法をご紹介します。
Webスクレイピングとは、Webサイトで公開されている情報のなかから必要な情報を取得するための技術のことです。
WebスクレイピングをつかえばWebサイトから必要な情報を自動的に取得することができます。いつもWebサイトから手作業で情報を取得している場合は、こちらでご紹介する方法を一度ご確認ください。
Pythonをつかった基本的な内容となりますが、こちらではWebスクレイピングをつかってWebサイトから取得した情報を「リスト形式」に変換して保存するところまでをご紹介をします。
具体的には、このようなWebサイトから情報を取得して、Excelなどの保存に適したリスト形式に変換して保存するところまでを解説します。
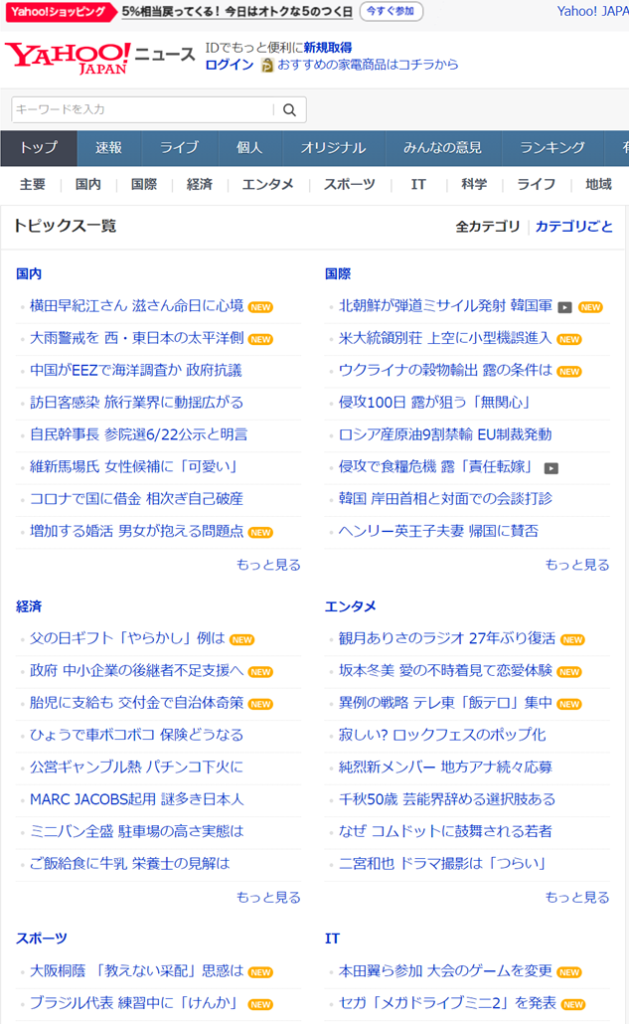
Webサイトの情報を取得して、このようなリスト形式に変換します。
「BeautifulSoup」+「Requests」と「Selenium」
有名なPythonのWebスクレイピングと言えば、「BeautifulSoup」+「Requests」をつかった方法と「Selenium」をつかった2つの方法があります。
「Selenium」をつかった方法では、Google ChromeなどのWebブラウザを自動操作することによってWebサイトの情報を取得します。
一方の「BeautifulSoup」と「Requests」をつかった方法では、Webブラウザを経由することなく「Requests」で直接Webサイトから情報を取得したうえで、「BeautifulSoup」をつかって取得情報を解析することによってWebサイトの情報を取得します。
ユーザー名やパスワードなどのログイン情報を入力する必要のあるWebサイトでは「Selenium」をつかってブラウザ操作をおこなう方法が適していますが、単純なWebページの情報取得であれば「BeautifulSoup」と「Requests」をつかった方法をオススメします。
理由としては、後者の方がシンプルな構成のため処理動作がスムーズなことが多いためです。
取得対象のWebサイト
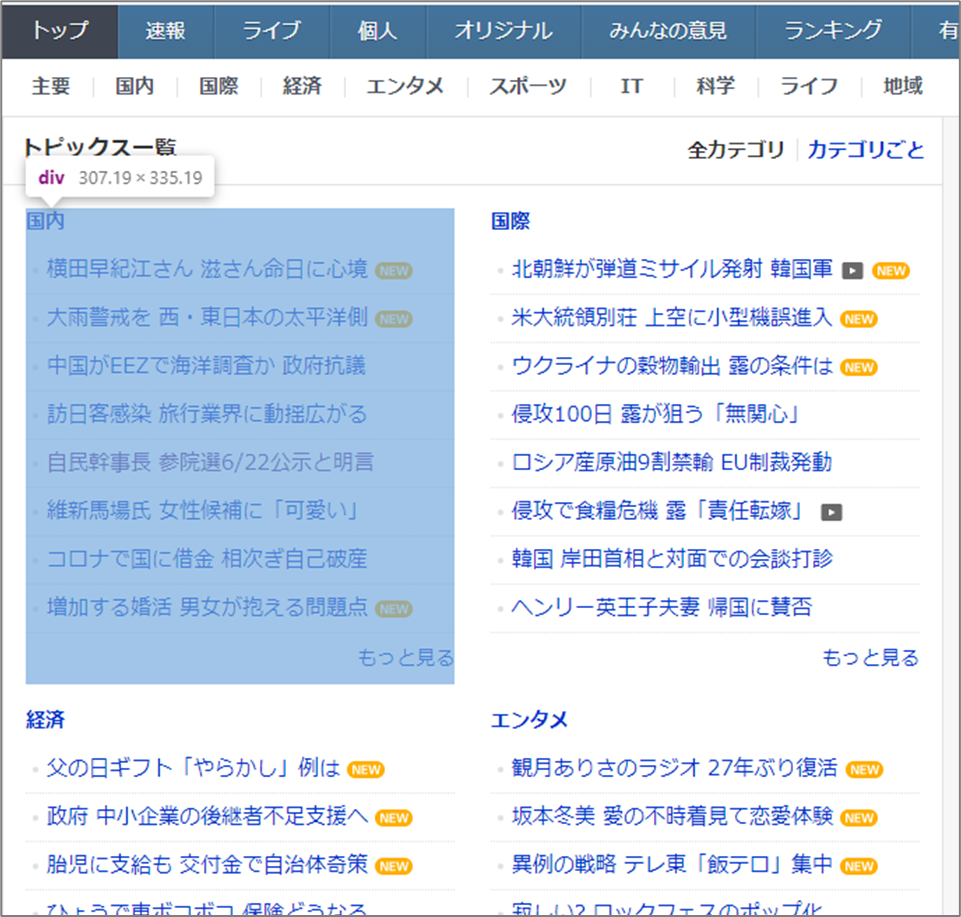
こちらでご紹介する取得対象となるWebサイトは「Yahoo!JAPAN ニュース」のトピック一覧です。
Webスクレイピングで情報を取得する場合、まずはHTMLの構成をしっかりと見たうえで取得対象となるタグ情報などを確認する必要があります。
HTMLの基礎知識
まずは、Webスクレイピングを実施するうえでHTMLの構造を理解する必要があります。
HTMLとは「Hyper Text Markup Language」の略称で、Webページを作成するための言語のことです。
Webスクレイピングでは、このWebサイトのページ情報をHTMLを指定することによって情報取得をします。
HTMLについての基礎知識を「【Python】SeleniumのためのHTMLの基礎知識」にてご紹介していますので、もしあまり馴染みがないようでしたらあわせてご確認ください。
HTMLの構成確認
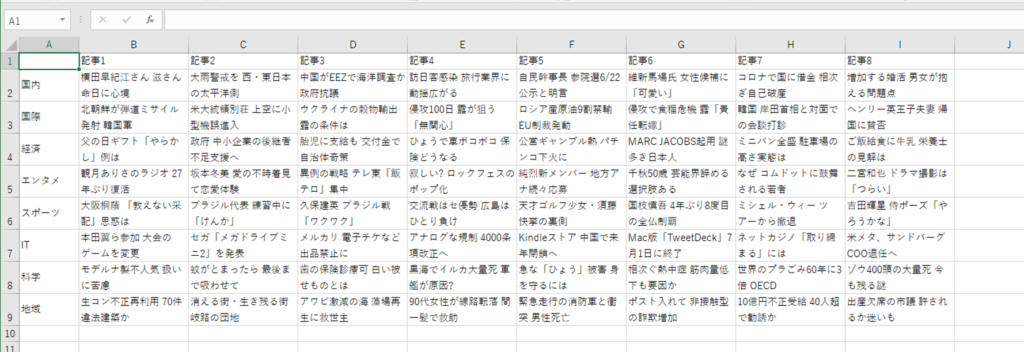
取得対象となるHTMLの構成を確認します。
今回は、「ul」タグの中の「li」タグのなかに含まれているテキストデータを取得対象としたいと思います。こちらのタグには各ニュースのテキスト情報(記事)が格納されています。

具体的にはこういったかたちでHTMLが構成されています。
(Google Chromeでは、Webページを開いた状態で「F12」を押下すれば表示されます。)
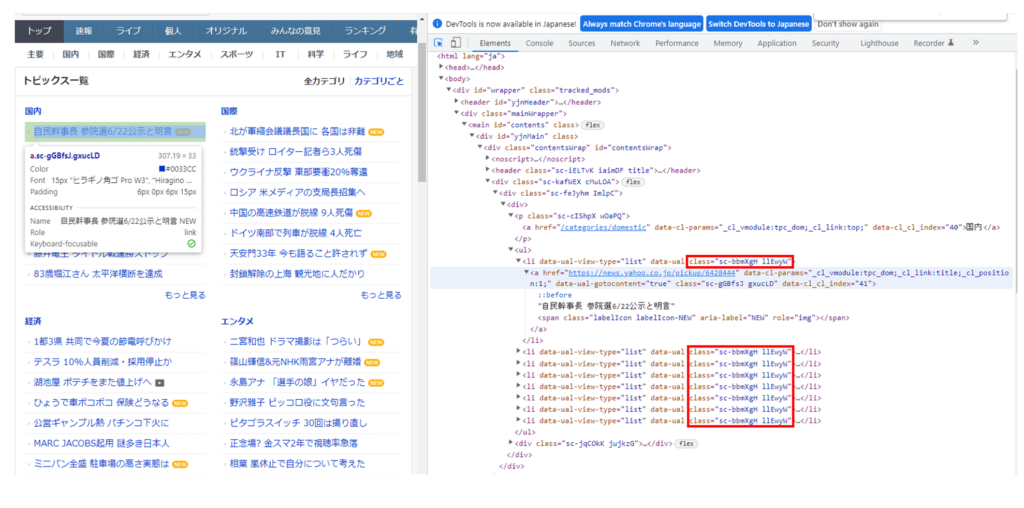
選択されている箇所がニュースのテキスト情報のひとつです。
こちらの場合では、各「li」タグのclass属性「sc-bbmXgH llEwyW」のなかの「a」タグにそれぞれニュースのテキスト情報が格納されています。
(上記の概略図では「li」タグのなかに記事が格納されていると図示していますが、厳密には「a」タグのなかにテキスト情報が格納されていることになります。)
ちなみに、上記の方法で取得されるニュースのテキスト情報は全部で「64個」あります。
Webスクレイピングの具体的な記述方法
Pythonをつかった具体的なWebスクレイピングの方法をサンプルコードをもちいてご紹介します。
手順1|事前準備
Webスクレイピングに必要なライブラリを準備します。
具体的には「requests」と「BeautifulSoup」を以下のとおりインポートします。
import requests from bs4 import BeautifulSoup
手順2|URLから情報取得
Webスクレイピングの対象となるURLを指定します。
指定したURLから「requests」をつかって情報を取得します。
url = "https://news.yahoo.co.jp/topics" res = requests.get(url)
手順3|取得情報の解析
「requests」で取得した情報を「BeautifulSoup」をつかって解析します。
「BeautifulSoup」関数をつかって、変数「res」に格納されている情報から「text」メソッドをつかって解析対象となるテキスト部分を取得したうえで、テキスト情報の解析方法を指定します。
なお、ここでの解析方法はHTMLに適した「”html.parser”」をつかっています。
soup = BeautifulSoup(res.text, "html.parser")
手順4|取得情報の確認
メソッド「prettify」をつかって取得情報を確認します。
「prettify」をつかうことによって、取得情報を階層的に表示させることができます。
print(soup.prettify())
こちらが「prettify」を使用した場合と、使用しなかった場合の比較です。
上側が使用した場合ですが、少し可読性があがっているかと思います。

手順5|取得情報の指定
取得した情報のなかから必要な情報のみをピックアップします。
「find_all」メソッドをつかって「li」タグのclass属性「sc-bbmXgH llEwyW」を指定します。
「find_all」メソッドをつかうことによって、複数要素をまとめて取得することができます。
(今回のWebページでは、指定場所に格納されているテキスト情報は「64個」ありますので「find_all」を採用しています。)
page = soup.find_all("li", attrs={"class":"sc-bbmXgH llEwyW"})
「Yahoo!ニュース」のクラス名は変更されることがあるようです。
そのため、こちらの方法でWebスクレイピングをおこなう際は、実際のWebサイトでクラス名を確認してから記述してください。
手順6|指定要素のリスト化
先ほどの手順で取得した変数「page」のテキスト部分のみを「for文」をつかって順番に取得したうえで、情報を新規リスト「article_list」に格納します。
article_list = []
for article in page:
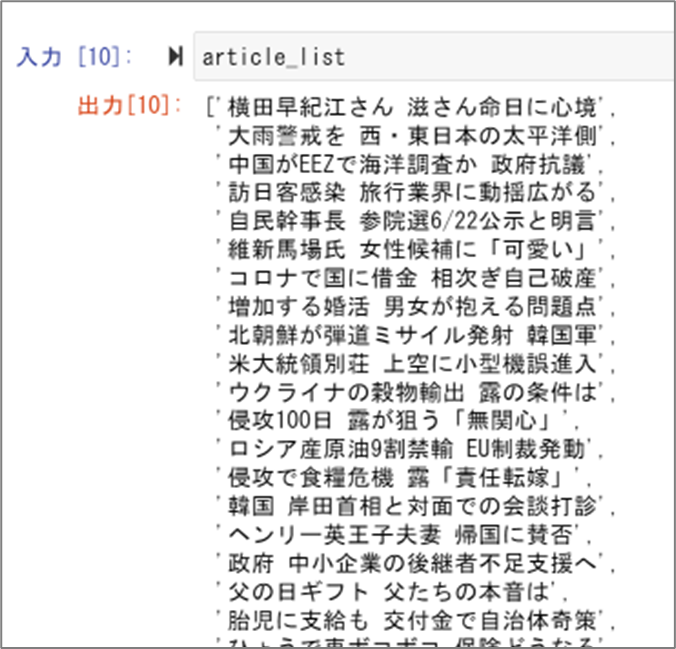
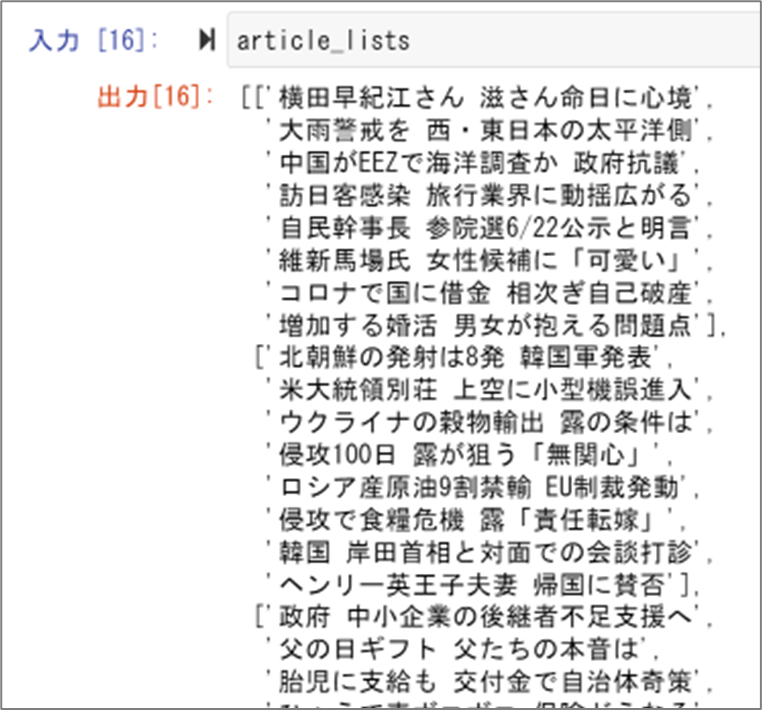
article_list.append(article.text)新規リスト「article_list」に格納されている値はこちらのとおりです。
ひとつのリストのなかに複数のテキスト情報(64個)が格納されている状況です。
手順7|リストの分割
これまでの手順で「64個」のテキスト情報がひとつのリストに格納されていますが、Webサイトの構成上、「国内」「国際」「経済」など全部で8つのカテゴリーに8つずつ記事が分類されていることがわかります。
こういった状態に対応させるために、リスト形式で取得した情報を8分割します。
article_lists = []
n = 8
for i in range(0, len(article_list), n):
article_lists.append(article_list[i:i+n])まず、リスト「article_lists 」を格納用に準備します。
つぎに「for文」をつかって記事を8つずつリスト「article_lists 」に追加していきます。
これを繰り返すことによって全部で「64個」の記事が8分割されることになります。
こちらが実行結果です。
リストの中にカテゴリー別のリストが含まれていることが確認できます。
手順8|カテゴリー名のリスト化
先ほどとおなじ要領でカテゴリー名を取得します。
「p」タグのclass属性「sc-cIShpX wOaPQ」の中にふくまれるテキスト情報を取得します。
このようにタグとclass属性を指定して値を取得します。
page2 = soup.find_all("p", attrs={"class":"sc-cIShpX wOaPQ"})こちらが出力結果です。
[<p class="sc-cIShpX wOaPQ"><a data-cl-params="_cl_vmodule:tpc_dom;_cl_link:top;" href="/categories/domestic">国内</a></p>,
<p class="sc-cIShpX wOaPQ"><a data-cl-params="_cl_vmodule:tpc_wor;_cl_link:top;" href="/categories/world">国際</a></p>,
<p class="sc-cIShpX wOaPQ"><a data-cl-params="_cl_vmodule:tpc_bus;_cl_link:top;" href="/categories/business">経済</a></p>,
<p class="sc-cIShpX wOaPQ"><a data-cl-params="_cl_vmodule:tpc_ent;_cl_link:top;" href="/categories/entertainment">エンタメ</a></p>,
<p class="sc-cIShpX wOaPQ"><a data-cl-params="_cl_vmodule:tpc_spo;_cl_link:top;" href="/categories/sports">スポーツ</a></p>,
<p class="sc-cIShpX wOaPQ"><a data-cl-params="_cl_vmodule:tpc_it;_cl_link:top;" href="/categories/it">IT</a></p>,
<p class="sc-cIShpX wOaPQ"><a data-cl-params="_cl_vmodule:tpc_sci;_cl_link:top;" href="/categories/science">科学</a></p>,
<p class="sc-cIShpX wOaPQ"><a data-cl-params="_cl_vmodule:tpc_loc;_cl_link:top;" href="/categories/local">地域</a></p>]
また、取得した変数「page2」の値から必要情報を抽出してリスト化します。
category_list = []
for category in page2:
category_list.append(category.a.text)リストに格納されている情報はこちらです。
['国内', '国際', '経済', 'エンタメ', 'スポーツ', 'IT', '科学', '地域']
手順9|リストの作成
ひとつのカテゴリーにたいして8つの記事があるため、適当な列名を設定します。
columns_list = ["記事1", "記事2", "記事3", "記事4", "記事5", "記事6", "記事7", "記事8"]
データを取り扱いやすくするために「Pandas」をつかってデータフレーム形式に変換します。
import pandas as pd df = pd.DataFrame(article_lists, columns=columns_list, index=(category_list))
変数「df」にはこのような形でデータが格納されています。
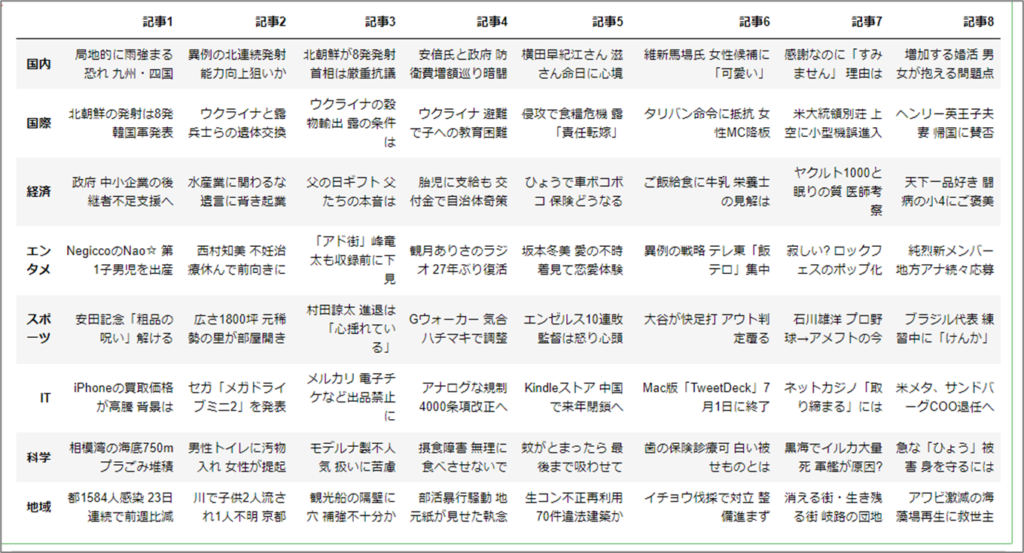
各手順で記事の内容に統一性がありませんが、本来はおなじ内容が掲載されます。
執筆に時間がかかっているため、取得されるWebページの情報が更新されているだけです。
手順10|リストの出力
さいごにリストをCSV形式で出力します。
df.to_csv("test_df.csv", encoding="utf-8-sig")この際に引数「encoding=”utf-8-sig”」の記述を忘れずにしましょう。
忘れてしまうと文字化けする可能性があります。
まとめ
Webサイトから取得した情報をリスト形式で出力するところまでのながれをご紹介しました。
Pythonでできる「Webスクレイピング」について具体的なイメージをもっていただけましたでしょうか?
こちらでご紹介した内容を応用することによって、さまざまなWebサイトから情報を自動的に取得することができます。ただし、一部のサイトでは「Webスクレイピング」による情報の取得を禁止している場合もありますので、本格的に利用される前にあらかじめサイト情報を調べておきましょう。
今回ご紹介したソースコードをまとめて掲載いたします。
import requests
from bs4 import BeautifulSoup
import pandas as pd
url = "https://news.yahoo.co.jp/topics"
res = requests.get(url)
soup = BeautifulSoup(res.text, "html.parser")
page = soup.find_all("li", attrs={"class":"sc-bbmXgH llEwyW"})
article_list = []
for article in page:
article_list.append(article.text)
article_lists = []
n = 8
for i in range(0, len(article_list), n):
article_lists.append(article_list[i:i+n])
page2 = soup.find_all("p", attrs={"class":"sc-cIShpX wOaPQ"})
category_list = []
for category in page2:
category_list.append(category.a.text)
columns_list = ["記事1", "記事2", "記事3", "記事4", "記事5", "記事6", "記事7", "記事8"]
df = pd.DataFrame(article_lists, columns=columns_list, index=(category_list))
df.to_csv("test_df.csv", encoding="utf-8-sig")なお、Pythonでは、Webブラウザを自動操作することによってWeb情報を取得する方法もあります。
「ログインやボタン操作が必要なWebサイトから情報を取得したい」とお考えの場合はこちらをご覧ください。


