

正規表現とは
「正規表現」とは、文字の並びをひとつのパターンで表現する方法です。
さまざまなパターンを設定することによってマッチするものを特定することができます。
これだけでは少しイメージしにくいかと思いますので、以下、具体例をもちいてご説明します。
glob関数をもちいたシンプルなマッチ
glob関数とは
「glob」とは、引数に指定されたパターンのファイルパスを取得することができる関数です。
ちなみにファイルパスとは、ファイルやフォルダの置き場をあらわす文字のことです。
例えば、デスクトップに置いてある「test.xlsx」というエクセルファイルは、「C:\Users\●●●\デスクトップ\test.xlsx」という様に表示されます。
(「●●●」にはユーザー名が入ります。)
glob関数とワイルドカード
glob関数とワイルドカードを組み合わせて、指定するフォルダーに含まれているファイル一覧を取得することができます。
ワイルドカードとは、「?(疑問符)」や「*(アスタリスク)」などの特殊記号のことです。「?」は任意の一文字を、「*」は任意の長さの文字列を指定するときに使用します。
glob関数とワイルドカードをつかって、以下のフォルダー「SampleFiles」に含まれる全てのファイル名を取得する方法をご紹介します。
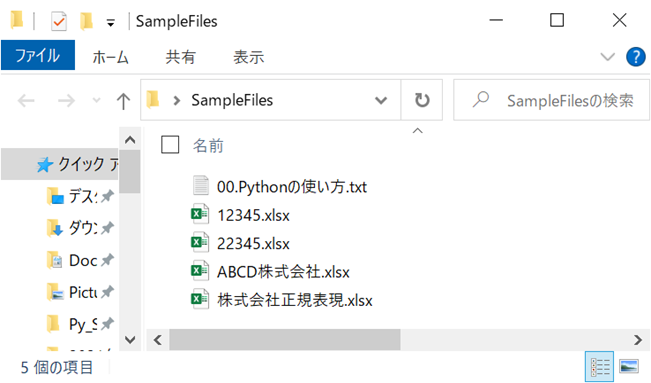
具体的なコードはつぎの通りです。
import glob files = glob.glob(r"C:\Users\●●●\デスクトップ\SampleFiles\*") print(files)
「ファイルパス(「C:」からはじまるもの)」の前にアルファベットの「r」が記述されていますが、これはエラーではありません。
「raw文字列」と言って、記号「\(環境によっては円記号 or バックスラッシュ)」をひとつの文字列として扱うための記述方法です。この「raw文字列」によって、「エスケープシーケンス」という特殊な制御文字を無効化することができます。
実行結果はこちらです。
['C:\\Users\\●●●\\デスクトップ\\SampleFiles\\00.Pythonの使い方.txt', 'C:\\Users\\●●●\\デスクトップ\\SampleFiles\\12345.xlsx', 'C:\\Users\\●●●\\デスクトップ\\SampleFiles\\22345.xlsx', 'C:\\Users\\●●●\\デスクトップ\\SampleFiles\\ABCD株式会社.xlsx', 'C:\\Users\\●●●\\デスクトップ\\SampleFiles\\株式会社正規表現.xlsx']
「*」をもちいて、指定フォルダーに含まれるファイル名の「すべての文字列」を指定しましたので、指定フォルダーの全ファイル一覧を取得することができました。
便宜上、一部の表示を加工していますが、サンプルコードおよび実行結果の「●●●」にはユーザー名が入ります。
正規表現のシンプルな使い方|3選
上記にてご説明しました「ワイルドカード」よりも詳細に文字列パターンを指定したい場合、「正規表現」という記法をもちいます。
「正規表現」によって指定することができる文字列のパターンは多岐に渡ります。
ほんの一部ではありますが、こちらではもっとも基本的な正規表現の使い方を具体例をもちいてご紹介します。
今回ご紹介する具体例はこちらです。
- 任意の文字を含むファイルを取得したい場合
- 会社コードを含むファイルを取得したい場合
- 特定の会社名を含むファイルを取得したい場合
なお、いずれのサンプルコードにも共通するものとして、あらかじめこちらのコードを実行していることを前提としています。
また、 以下すべての「●●●」 の部分にはユーザー名が入ります。
import glob files = glob.glob(r"C:\Users\●●●\デスクトップ\SampleFiles\*")
任意の文字を含むファイルを取得したい場合
こちらでは、ファイル名に「株式会社」が含まれているファイルを取得する例をご紹介します。
import re
pattern1 = re.compile("株式会社")
for file in files:
result_pattern = re.findall(pattern1, file)
if result_pattern:
print(file)こちらが実行結果です。
C:\Users\●●●\デスクトップ\SampleFiles\ABCD株式会社.xlsx
C:\Users\●●●\デスクトップ\SampleFiles\株式会社正規表現.xlsx以下、コードの内容をかんたんに解説いたします。
まずは、正規表現「re」をインポートします。
つぎに変数「pattern1」に正規表現のcompile関数をつかって値を代入します。
compile関数の引数に指定文字「株式会社」を入力しています。これによって、文字列として「株式会社」が含まれるパターンを指定することができます。
そして、繰り返し処理のfor文をもちいて、glob関数をつかって取得した変数「files」の値を正規表現をつかってマッチ判定をします。
re.findall(): 条件にマッチする値をリスト形式で取得
さいごに判定結果で該当するものを表示させます。
会社コードを含むファイルを取得したい場合
こちらでは、「5桁の数値」を含むファイルを取得する例をご紹介します。
import re
pattern2 = re.compile(r"\d{5}")
for file in files:
result_pattern = re.findall(pattern2, file)
if result_pattern:
print(file)こちらが実行結果です。
C:\Users\●●●\デスクトップ\SampleFiles\12345.xlsx
C:\Users\●●●\デスクトップ\SampleFiles\22345.xlsx先ほどの例とほとんど同じですが、compile関数の引数を「r”\d{5}“」に変更しています。
こちらは正規表現の特殊な指定方法ですが、”「\d」は10進法の数値に一致するもの”を表していて、”「{n}」はn回分一致するもの”を表しています。これらふたつを組み合わせた形で構成されています。
つまり、正規表現をつかって”10進法の数値が5回一致するもの”を指定しています。
特定の会社名を含むファイルを取得したい場合
あらかじめ準備したリスト(会社一覧など)に基づいてファイル取得を判定する例をご紹介します。
事前にデスクトップに「社名一覧.xlsx」を準備しています。
このエクセルファイルには、抽出対象となる会社情報を掲載してあります。
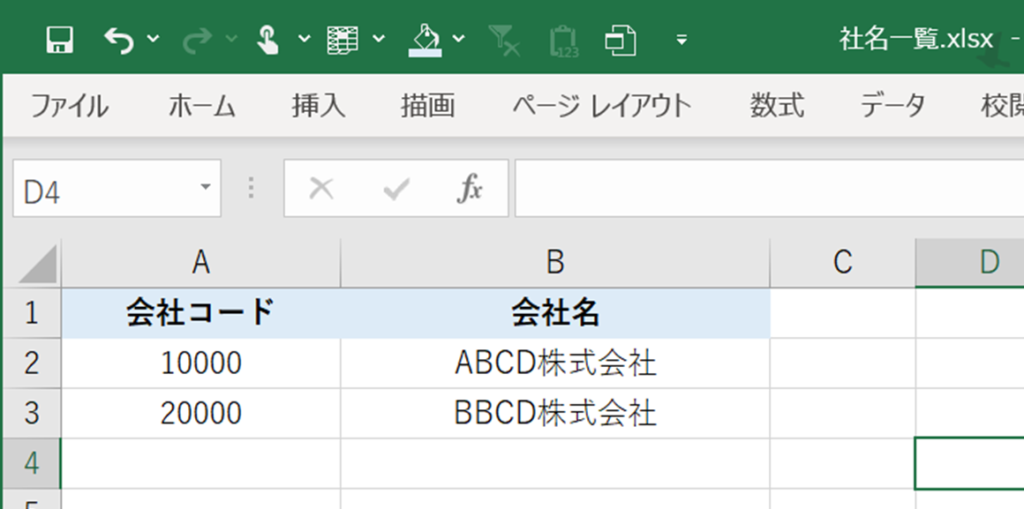
こちらがサンプルコードです。
import re
import pandas as pd
excel_file = (r"C:\Users●●●\デスクトップ\社名一覧.xlsx")
df = pd.read_excel(excel_file)
df_list = df["会社名"].values
for file in files:
for customer in df_list:
if re.findall(customer, file):
print(file)こちらが実行結果です。
「社名一覧.xlsx」 に掲載されている会社名をふくむファイルを取得することができました。
C:\Users\●●●\デスクトップ\SampleFiles\ABCD株式会社.xlsx
以下、順番に解説します。
エクセルデータの読込
エクセルデータの取り込みには、外部ライブラリの「pandas」を使用しています。
まずは「pandas」をインポートします。
変数「excel_file」にファイルパスを代入してから、read_excel関数をつかってエクセルファイルを読み込みます。
(変数「excel_file」を介さずに直接ファイルパスを指定する方法でも問題ありません。)
import pandas as pd excel_file = (r"C:\Users●●●\デスクトップ\社名一覧.xlsx") df = pd.read_excel(excel_file)
ここまでの結果を出力した場合、このような状態になります。
エクセルファイル「 社名一覧.xlsx 」の内容が読み込めていることが確認できます。
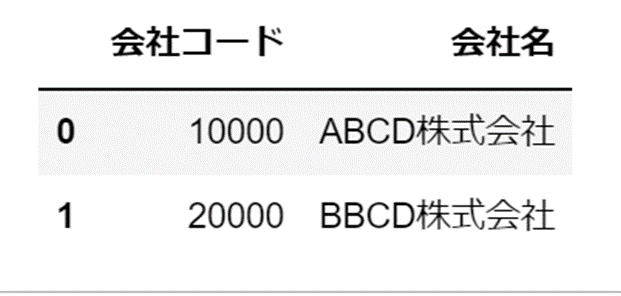
取得したデータから値を抽出
「pandas」では、このような二次元のデータをDataFrameとして様々なかたちで編集することができますが、今回は会社名を取り出す方法に焦点をしぼってご説明をします。
変数「df」に抽出したい列名「会社名」を指定した上で、「values」をつかって値を取得します。
df["会社名"].values
こちらの実行結果はつぎの通りです。
「会社名」の情報のみが抽出されています。
['ABCD株式会社' 'BBCD株式会社']繰り返し処理で「会社名」を含むファイルを抽出
繰り返し処理をつかって指定フォルダー「SampleFiles」の中から、特定の「会社名」を含むファイルを抽出します。
for file in files:
for customer in df_list:
if re.findall(customer, file):
print(file)こちらが実行結果です。
「ABCD株式会社」を含むファイルが取得されています。
C:\Users\●●●\デスクトップ\SampleFiles\ABCD株式会社.xlsx
以下、順番に解説をします。
まずは、一度目のfor文をつかって変数「files」の値をひとつずつ取り出します。
変数「files」に含まれるデータはこちらです。
['C:\\Users\\●●●\\デスクトップ\\SampleFiles\\00.Pythonの使い方.txt', 'C:\\Users\\●●●\\デスクトップ\\SampleFiles\\12345.xlsx', 'C:\\Users\\●●●\\デスクトップ\\SampleFiles\\22345.xlsx', 'C:\\Users\\●●●\\デスクトップ\\SampleFiles\\ABCD株式会社.xlsx', 'C:\\Users\\●●●\\デスクトップ\\SampleFiles\\株式会社正規表現.xlsx']
つぎに、二度目のfor文をつかって変数「df_list」に含まれる値をひとつずつ取り出します。
変数「df_list」 に含まれるデータはこちらです。
['ABCD株式会社' 'BBCD株式会社']この2つのデータを正規表現をつかって順番にマッチ判定を繰り返しています。
具体的なプログラムの流れはつぎの通りです。
「 C:\\Users\\●●●\\デスクトップ\\SampleFiles\\00.Pythonの使い方.txt 」に 「ABCD株式会社」が含まれているかを確認
「 C:\\Users\\●●●\\デスクトップ\\SampleFiles\\00.Pythonの使い方.txt 」に 「BBCD株式会社」が含まれているかを確認
「 C:\\Users\\●●●\\デスクトップ\\SampleFiles\\12345.xlsx 」に 「ABCD株式会社」が含まれているかを確認
「 C:\\Users\\●●●\\デスクトップ\\SampleFiles\\12345.xlsx 」に 「BBCD株式会社」が含まれているかを確認
(以下、順につづく)
以上の流れを経て指定条件にマッチするファイルが抽出されます。
まとめ
今回は具体例をつかって正規表現の基本的な使い方をご紹介いたしました。
正規表現はさまざまなパターンで使用することができます。今回ご紹介した内容はほんの一部にすぎませんので、もし活用ができそうな場合はお調べいただくことをオススメします。

