「Power Automate Desktop」のアクション「PDFから画像を抽出」について、具体例をつかって解説をします。
具体的なアクションの使い方
こちらのアクションをつかって、PDF ファイルから画像を抽出します。
PDFファイル
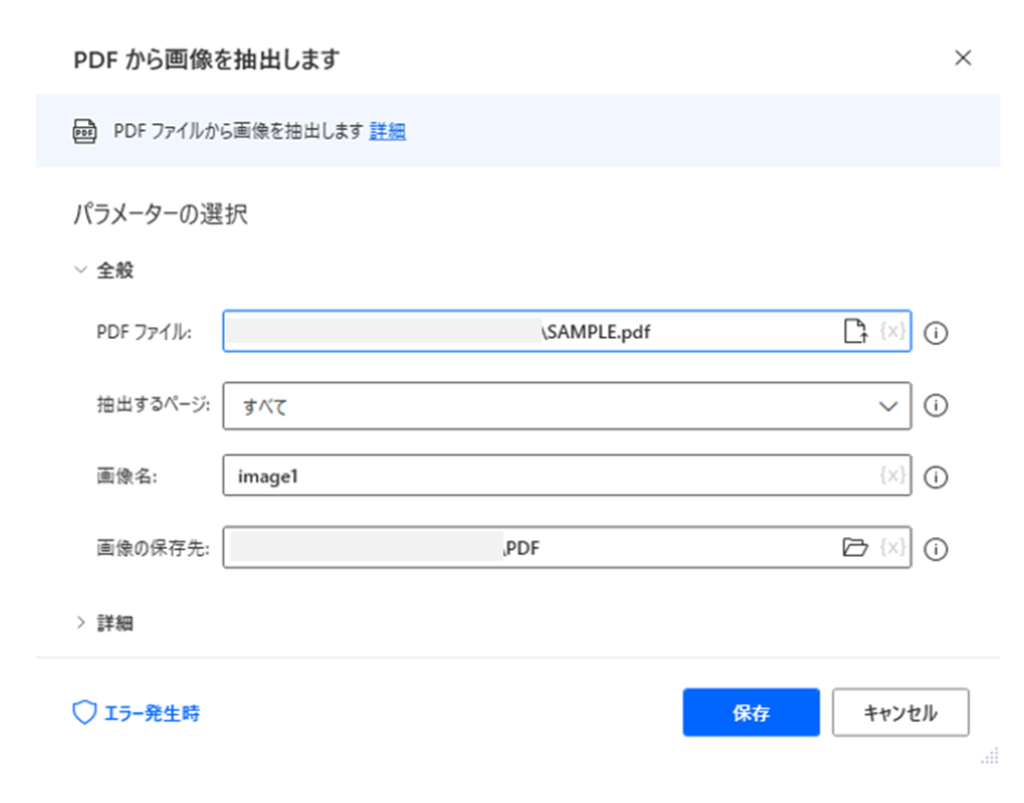
こちらで指定したPDF ファイルから画像を抽出します。
抽出するページ
パラメーターの選択「抽出するページ」では、以下の項目からひとつを選択します。
| 選択項目 | 内容 |
| すべて | 指定したPDFファイルのすべての画像を対象とします。 |
| 単一 | 画像取得の対象とするPDFファイルの「単一ページ番号」を指定します。 |
| 範囲 | 画像取得の対象とするPDFファイルの「開始ページ番号」と「終了ページ番号」を指定します。 |
画像名
パラメーターの選択「画像名」について、複数の画像ファイルを抽出した場合のファイル名は「(画像名の入力値)_0」、「(画像名の入力値)_1」、「(画像名の入力値)_2」のように、末尾に番号が割り振られます。
画像の保存先
PDF ファイルから抽出された画像の保存先を指定します。
パスワード
PDFがパスワードで保護されている場合は、PDFファイルのパスワードを入力します。パスワードで保護されていない場合は、空白で問題ありません。
活用事例
こちらのPDF ファイル(ファイル名「SAMPLE.pdf」)を使ってご紹介します。
先ほどのアクションでこちらのファイルを指定して結果を確認します。
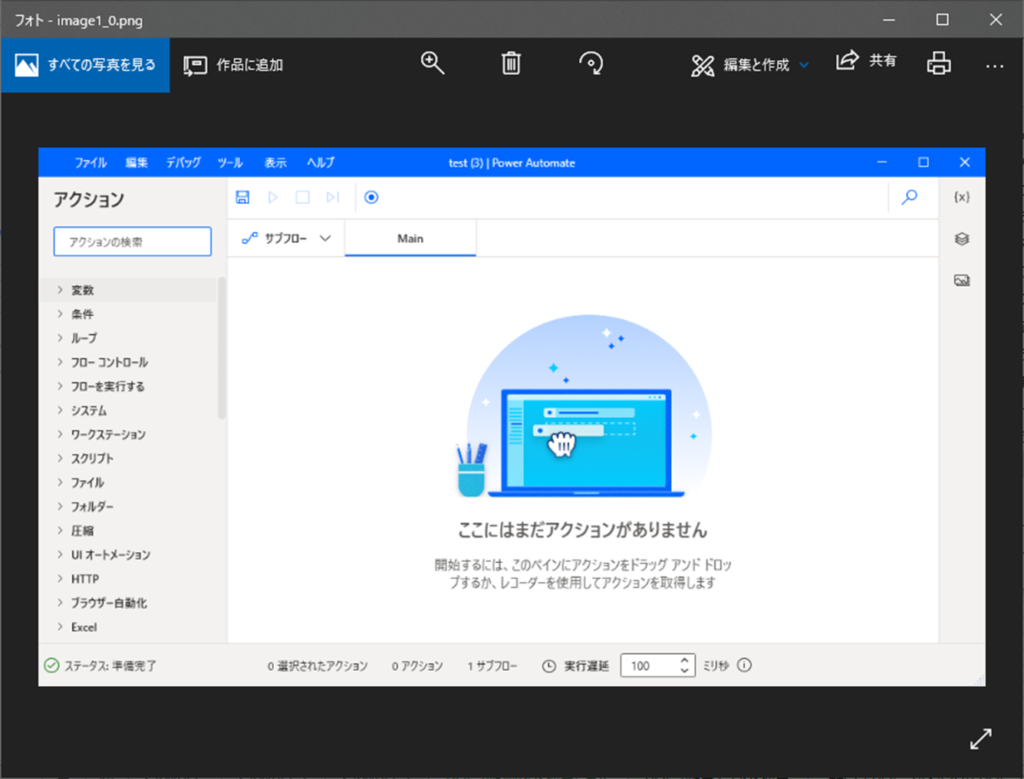
こちらが実行結果です。
テキストをのぞく画像部分だけが、画像ファイル「image1_0.png」として取得されました。