

無償化された「Power Automate Desktop」の基本的な使い方や、PDFからエクセルへのデータ転記方法を具体例をつかってご紹介します。
「Power Automate Desktop」とは
「Power Automate Desktop」とは、Microsoftが提供する無料のRPAツールです。
「Power Automate Desktop」は「Power Automate」の機能の一部で、「Microsoft Power Platform」のサービスの1つでもあります。
参考:【Power Automate Desktop】Microsoftの無料RPAツールの概要
アクション|PDFの操作一覧
テキストおよび画像PDFファイルの内容を自動化します。
| 項目 | 内容 |
| PDF からテキストを抽出 | PDF ファイルからテキストを抽出。 |
| PDFからテーブルを抽出する | PDFファイルからテーブルを抽出する。 |
| PDF から画像を抽出 | PDF ファイルから画像を抽出します。 |
| 新しい PDF ファイルへの PDF ファイル ページの抽出 | PDF ファイルから新しい PDF ファイルに ページを抽出します。 |
| PDF ファイルを統合 | 複数の PDF ファイルを新しいファイルに統合します。 |
スポンサーリンク
操作例|PDFからエクセルにテキストデータを転記
かんたんな自動化の作成をとおして「Power Automate Desktop」の使い方をご紹介します。
テキストと画像が含まれるPDFデータから、テキストのみを抽出してエクセルにデータ転記する処理の作成例です。
「Power Automate Desktop」で自動化する内容はこちらです。
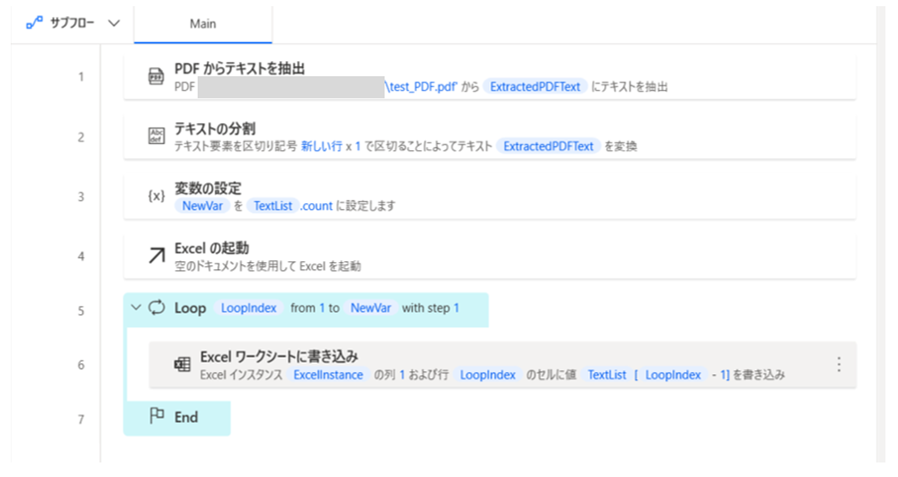
なお、今回使用するPDFファイルはこちらです(ファイル名:test_PDF.pdf)。
適当なテキストと画像で構成されています。

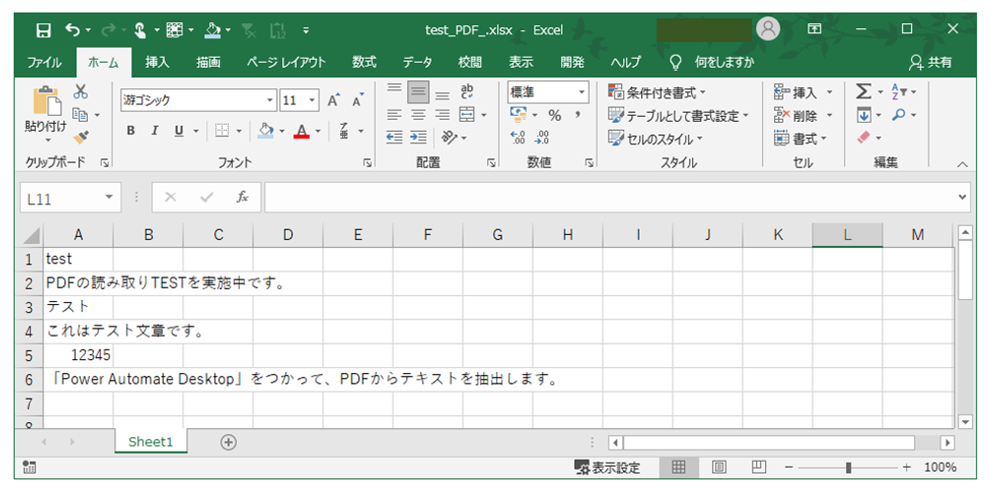
実行結果はこちらです。
行ごとにPDFデータがエクセルへと転記されていることが確認できます。
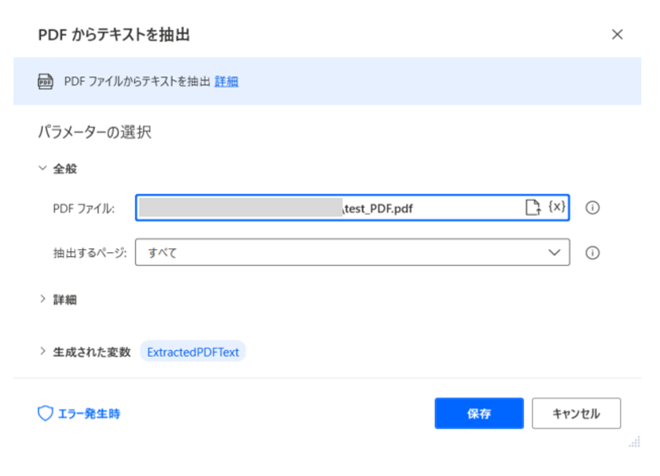
手順1|PDF からテキストを抽出
PDFからテキストを抽出するために対象となるPDFを指定します。
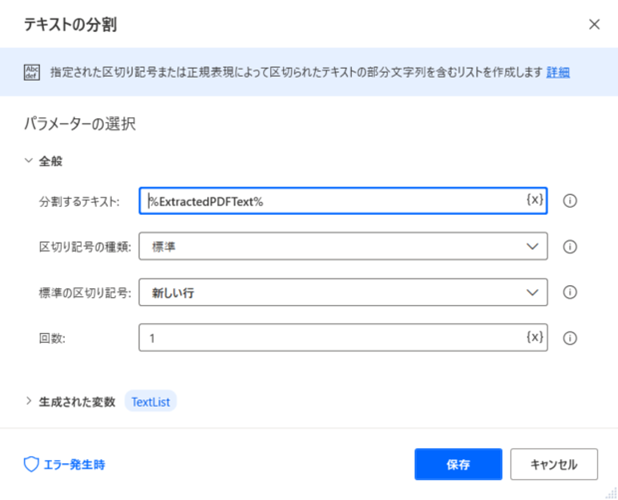
手順2|テキストの分割
手順1にて抽出したPDFのテキストデータを行ごとに分割します。
のちの手順6でエクセルの各行にデータ転記をするための事前準備です。
参考:【Power Automate Desktop】テキストの使い方を解説
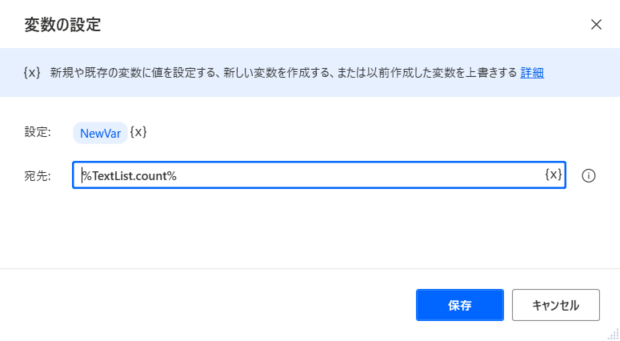
手順3|変数の設定
ループ処理のための変数を設定します。
手順2で生成された変数「TextList」に「.count」をつかうことによって、「リストに格納されている項目の数」を抽出します。
今回の例で取得される値は「6」です。
参考:【Power Automate Desktop】変数の使い方を解説
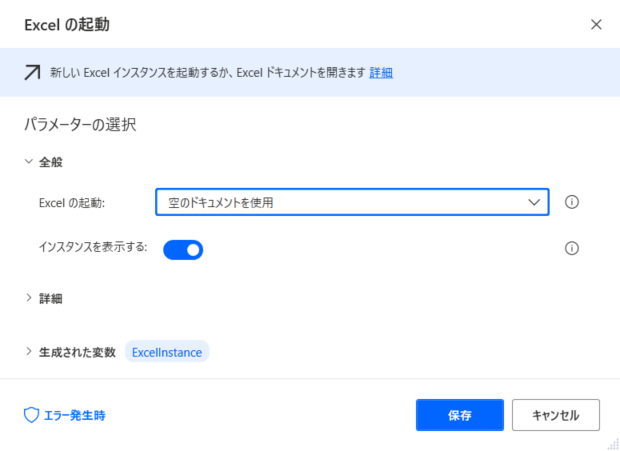
手順4|Excel の起動
データ出力用に新規エクセルを開きます。
参考:【Power Automate Desktop】エクセルでできることや使い方を紹介
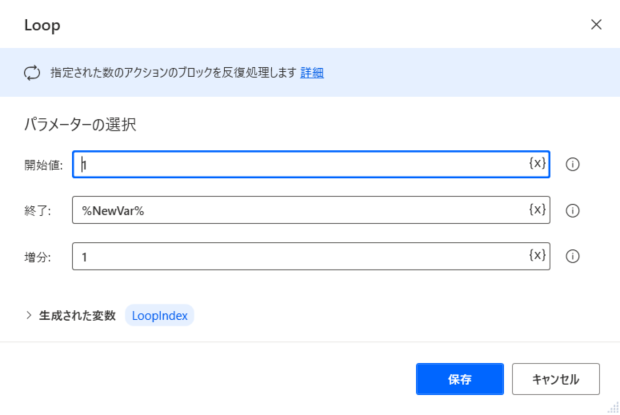
手順5|Loop
ループ処理を指定します。
さきほどの手順3で生成された変数「NewVar」を終了値とします(値は「6」)。
今回の例で取得された値は「6」ですが、PDFの内容によって取得されるデータに違いがあるため変数をつかって繰り返し回数を指定しています。
参考:【Power Automate Desktop】ループ処理の使い方を解説
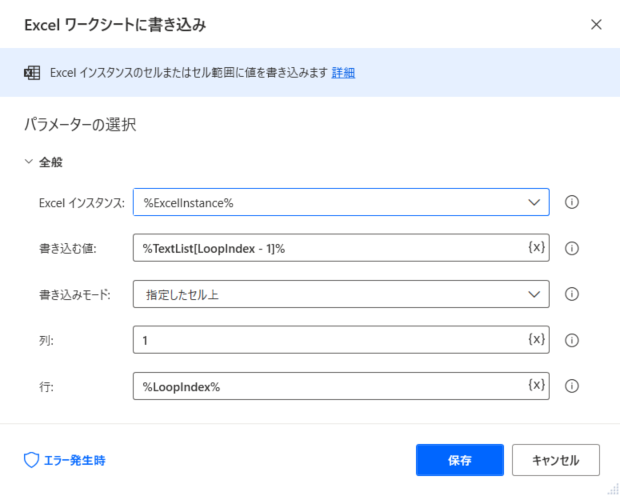
手順6|Excel ワークシートに書き込み
PDFから取得したデータをエクセルに転記します。
エクセルに書き込む値は、それぞれ各行に転記するために手順2「テキストの分割」で生成された変数「TextList」からひとつずつ順番にデータを取り出すことによってデータを分割した状態にします。
リストデータ
まず前提としてリストデータの取り扱いについてのご説明をします。
こちらが変数「TextList」に格納されているデータです。
| インデックス番号 | データの内容 |
| 0 | test |
| 1 | PDFの読み取りTESTを実施中です。 |
| 2 | テスト |
| 3 | これはテスト文章です。 |
| 4 | 12345 |
| 5 | 「Power Automate Desktop」をつかって、PDFからテキストを抽出します。 |
データの格納場所は、インデックス番号によって分類されています。
特徴としてこのインデックス番号は「1」からはじまるのではなく、「0」からはじまる点があげられます。
そのため、変数「TextList」の1番目に格納されている値である”test”を取り出したいときは、”%TextList[0]%”と記述する必要があります(記号の角カッコを使います)。
インデックス番号
つぎにインデックス番号の指定についてご説明をします。
書き込む値「TextList[LoopIndex – 1]」と指定しています。
「-1」で調整することによって正しいインデックス番号を取得しています。
具体的に取得されるデータはつぎのとおりです。
| Loop Index | Loop Index – 1 | データの内容 |
| 1 | 0 | test |
| 2 | 1 | PDFの読み取りTESTを実施中です。 |
| 3 | 2 | テスト |
| 4 | 3 | これはテスト文章です。 |
| 5 | 4 | 12345 |
| 6 | 5 | 「Power Automate Desktop」をつかって、PDFからテキストを抽出します。 |
なお、エクセルに書き込む行は「1からはじまる」ため、変数「LoopIndex」をそのまま指定しています。
スポンサーリンク
まとめ
今回は、具体例なPDFをつかった操作例をご紹介いたしました。
「PDF からテキストを抽出」についての活用事例をご紹介いたしましたが、他の「PDF」に関連するアクションはこちらからご確認ください。
| 項目 | 内容 |
| PDF から画像を抽出します | PDF ファイルから画像を抽出します。 |
| PDF からテキストを抽出 | PDF ファイルからテキストを抽出。 |
| 新しい PDF ファイルへの PDF ファイル ページの抽出 | PDF ファイルから新しい PDF ファイルに ページを抽出します。 |
| PDF ファイルを統合 | 複数の PDF ファイルを新しいファイルに統合します。 |
また、その他のアクションについてはこちらでご紹介しております。
こちらに「Power Automate Desktop」でできることや基本的な操作方法をまとめていますので、もしご興味がございましたら一度ご覧ください。


