

「Power Automate Desktop」のアクション「PDFからテーブルを抽出する」について、具体例をつかって解説をします。
PDFファイルから指定したページの範囲でテーブルを抽出することができます。
具体的なアクションの使い方
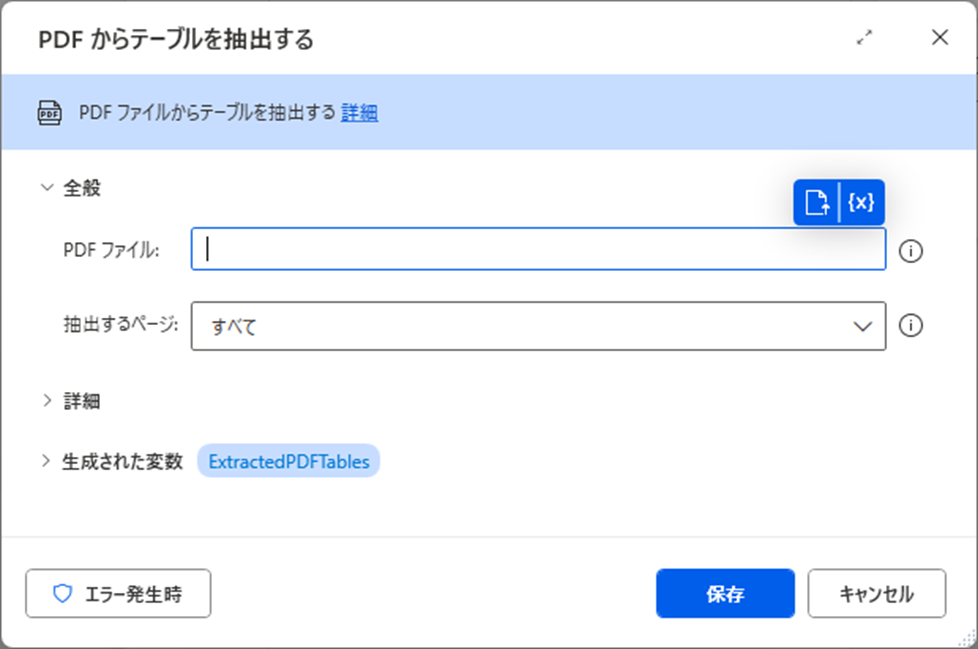
PDFファイル
テーブルを抽出する対象となるPDFファイルを指定します。
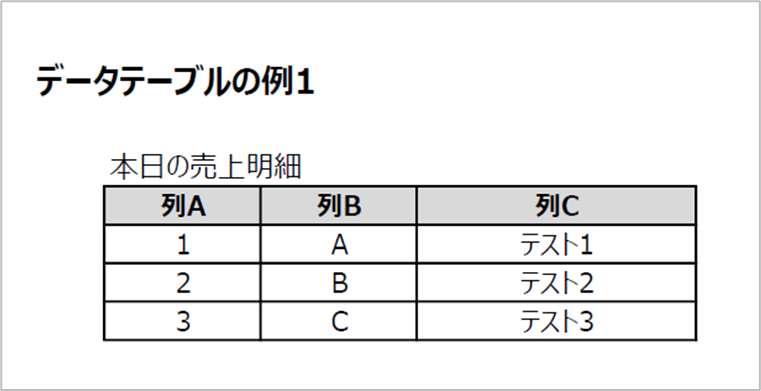
今回はこちらのPDFファイル(ファイル名「Sample_PDF」)を使用して動作を説明します。2ページで構成されており、それぞれのページにデータテーブル(表形式の明細)が掲載されています。
こちらが1ページ目です。
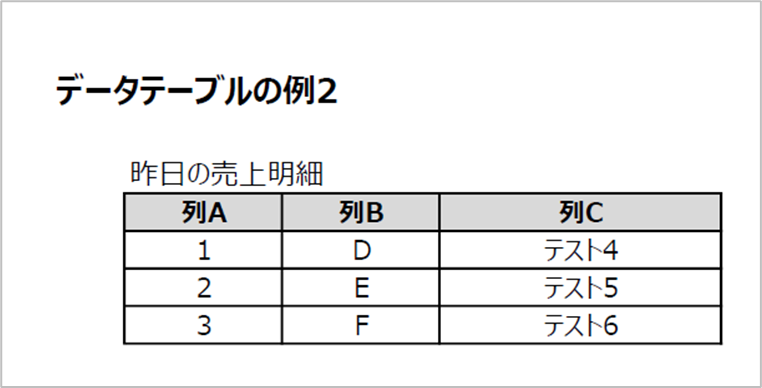
こちらが2ページ目です。
抽出するページ
テーブルを抽出するページ数(すべてのページ、単一ページ、または1つのページ範囲)を指定します。
すべて
すべてのページ範囲を指定する際に使用します。
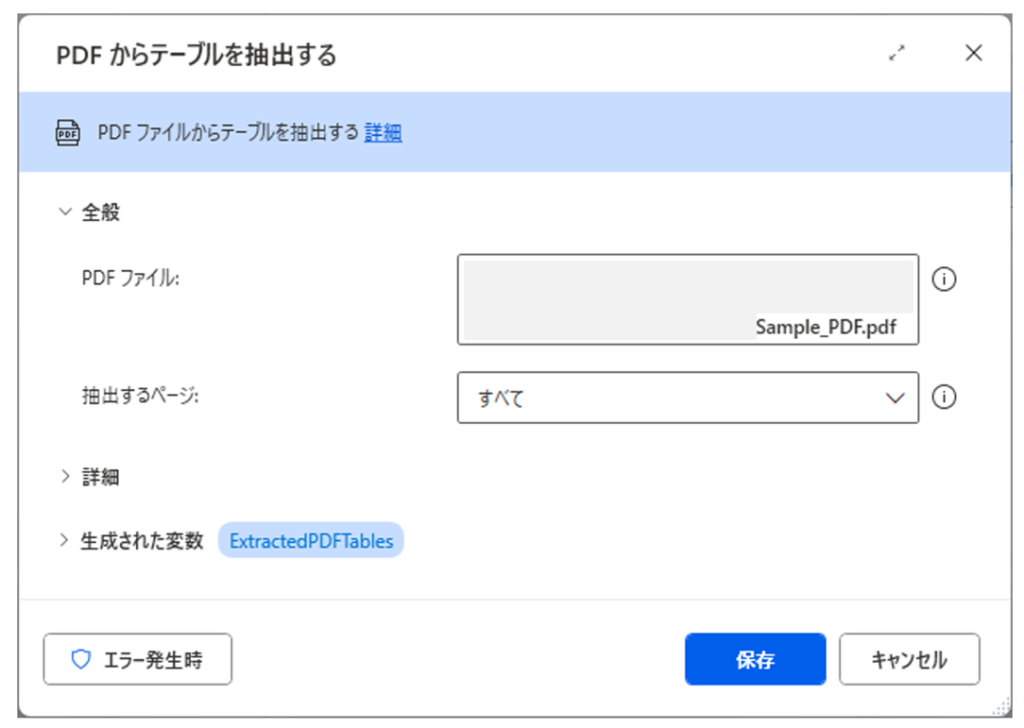
こちらが実行結果です。
2つのテーブル情報が取得されていることが確認できます。
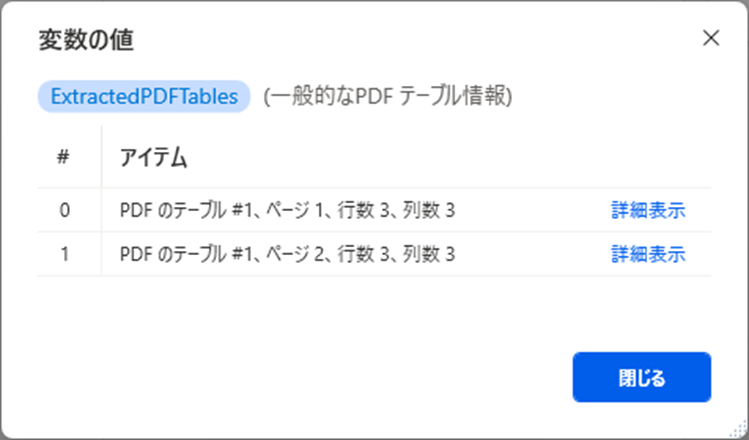
続けて、それぞれの「詳細表示」を確認しましょう。
まずは、1つ目の詳細です。
PDFの1ページ目に掲載されていたデータテーブルが取得されていることが確認できます。
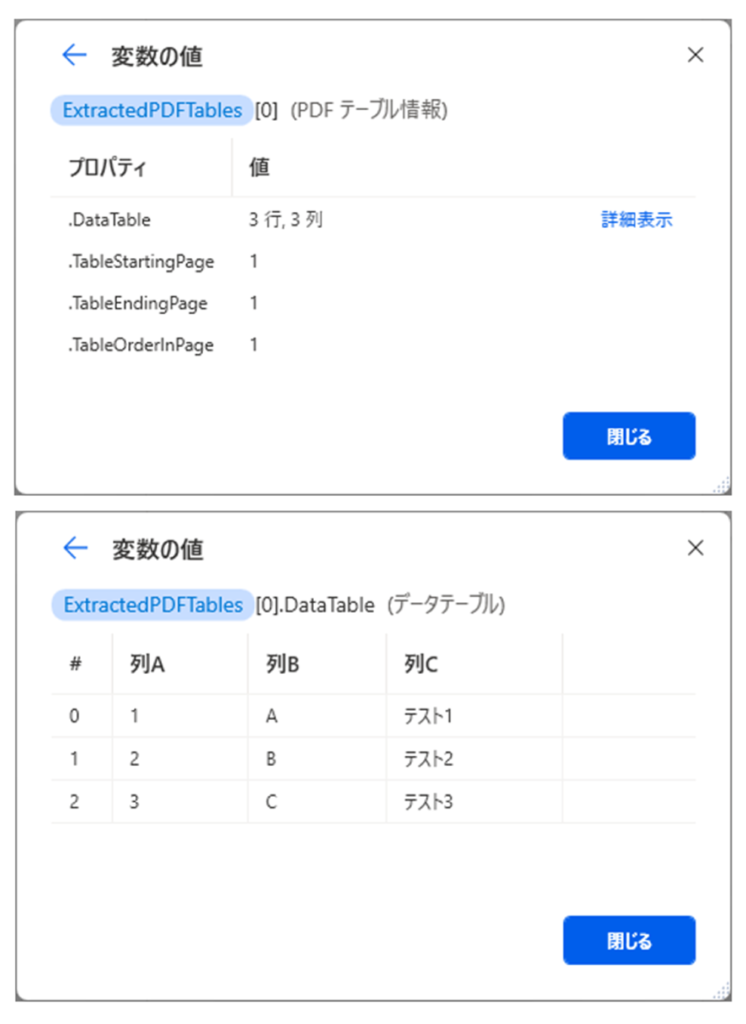
つぎに、2つ目の詳細です。
PDFの2ページ目に掲載されていたデータテーブルが取得されていることが確認できます。
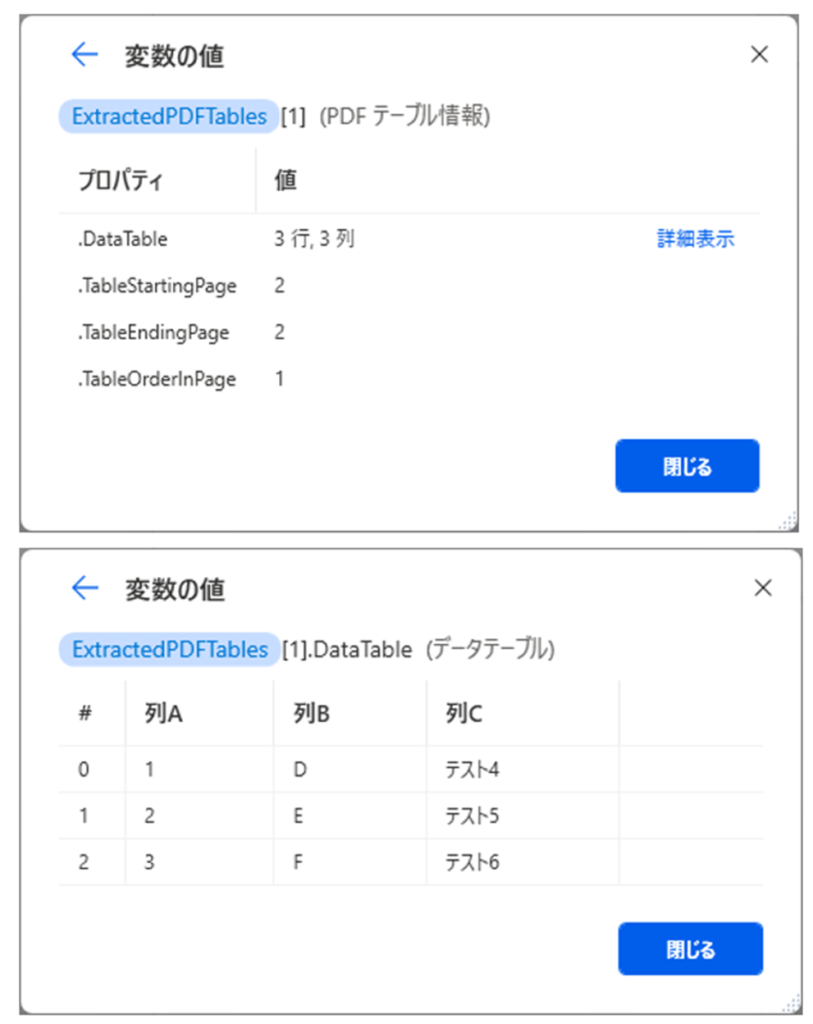
単一
単一のページを指定する際に使用します。
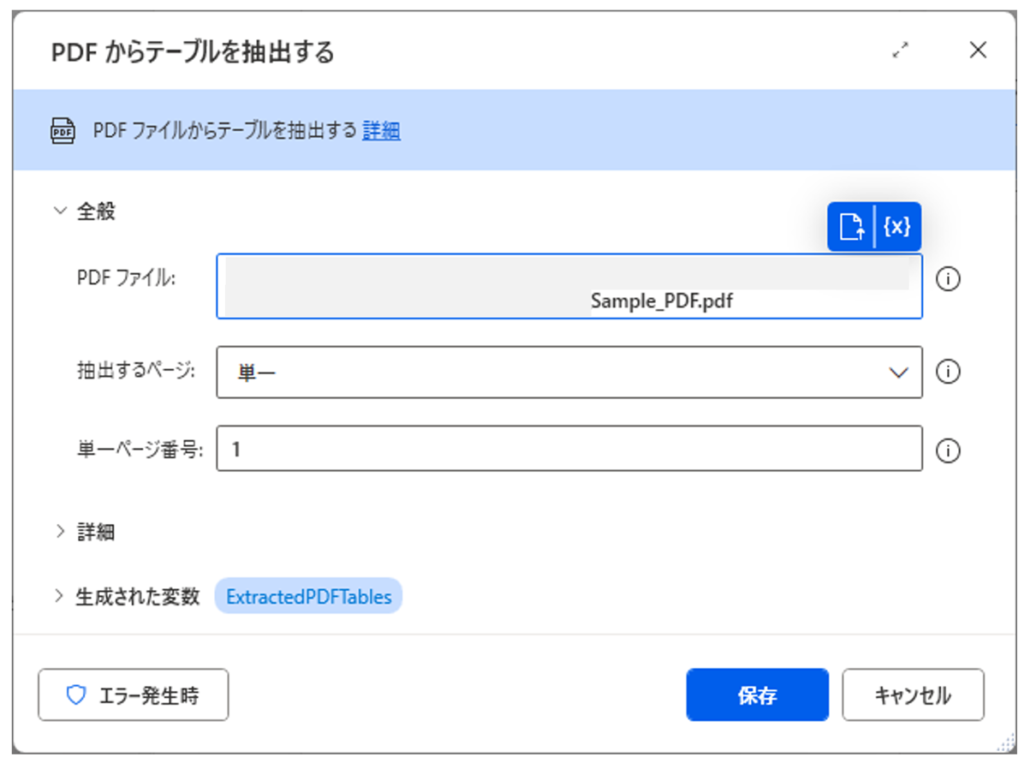
こちらが実行結果です。
指定したページのテーブル情報が取得されていることが確認できます。
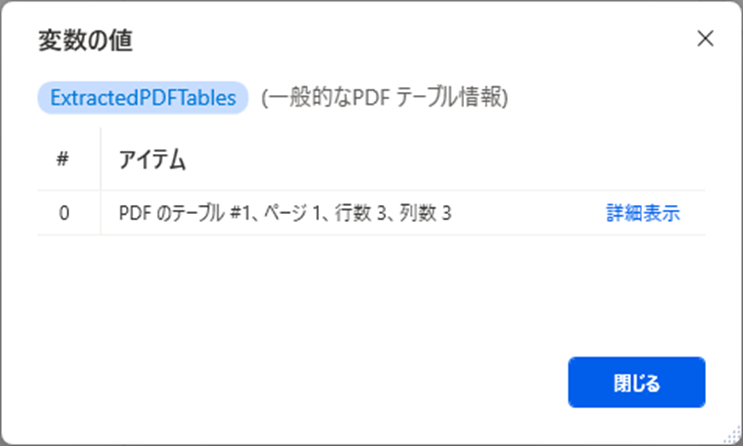
「詳細表示」の値はこちらのとおりです。
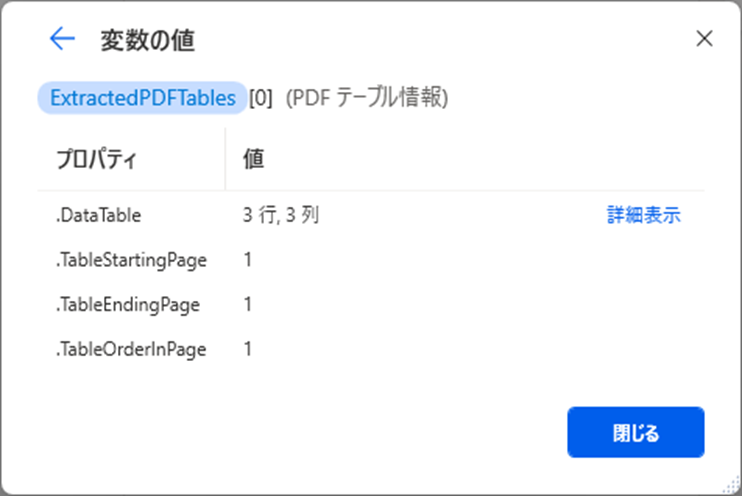
さらに「詳細表示」の値はこちらのとおりです。
データテーブルの情報が取得されていることが確認できます。
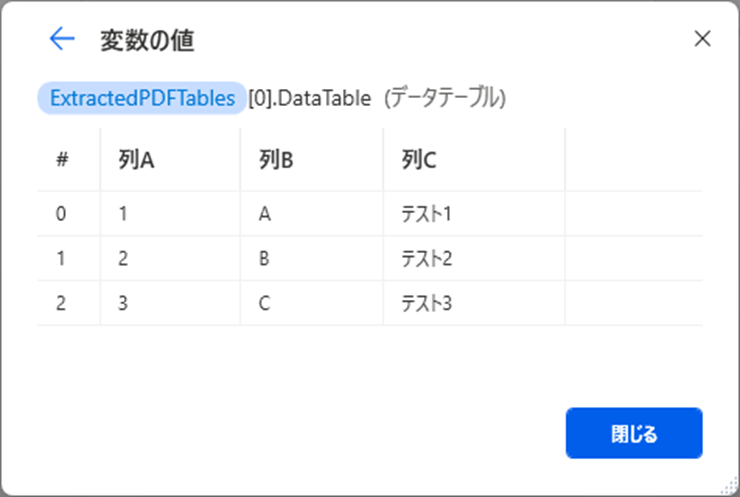
範囲
「開始ページ番号」と「終了ページ番号」で、ページの範囲を指定する際に使用します。
任意のページ範囲を指定することがきますが、本例では「開始ページ番号:2」と「終了ページ番号:2」を入力することによって、2ページ目のみが指定されている状況です。
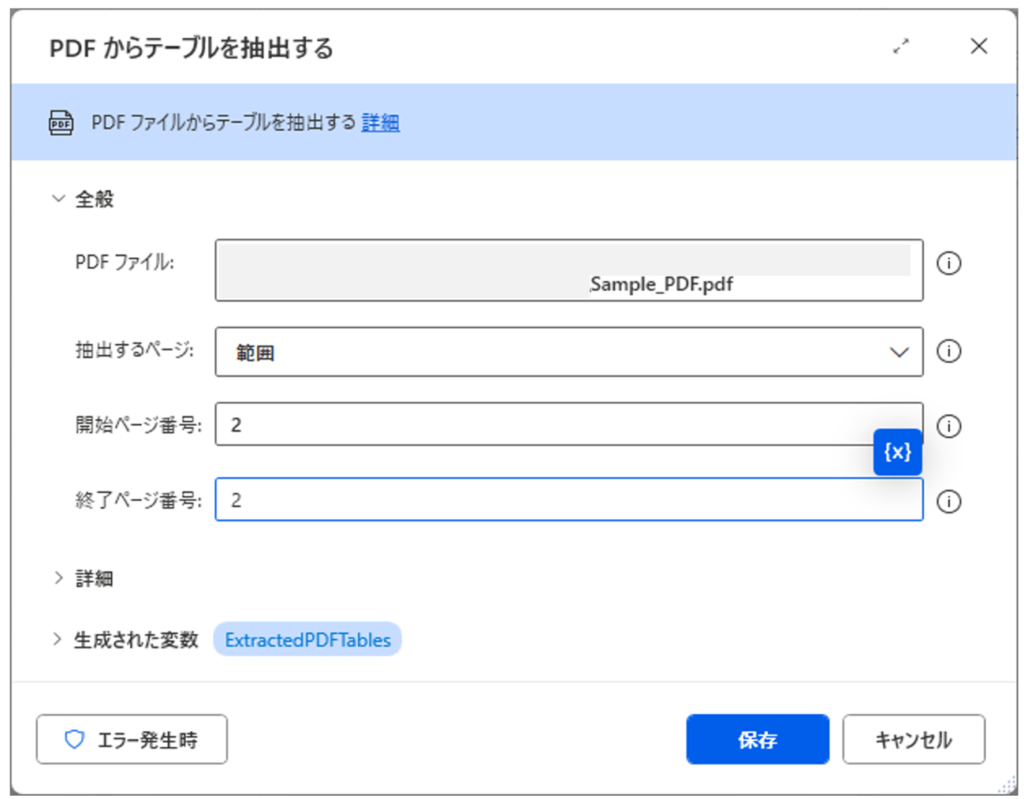
こちらが実行結果です。
1つのデータテーブルが取得されていることが確認できます。
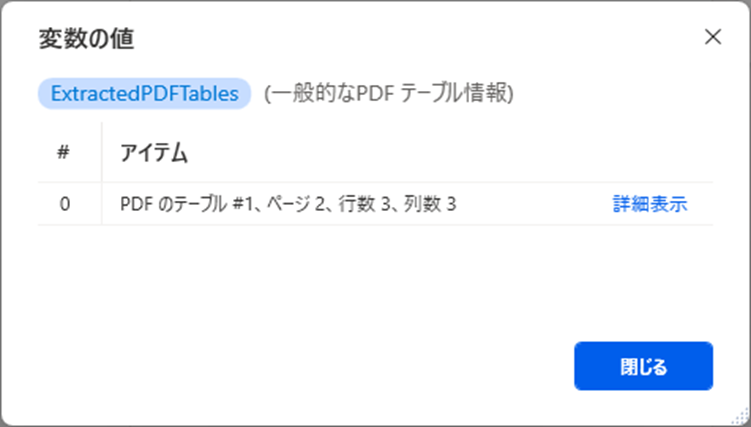
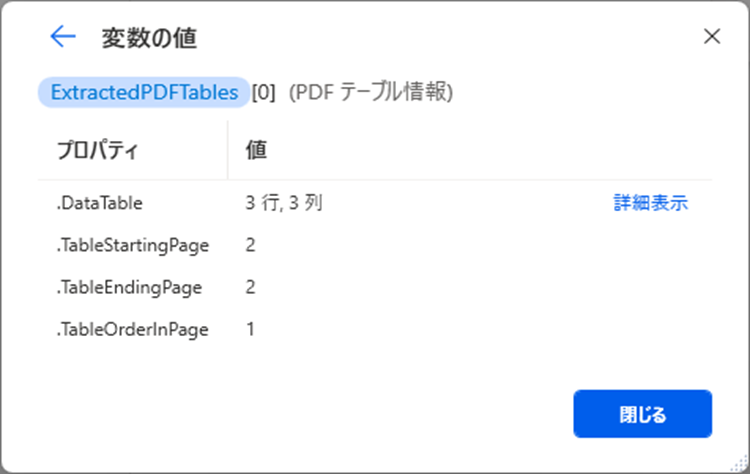
「詳細表示」の値はこちらのとおりです。
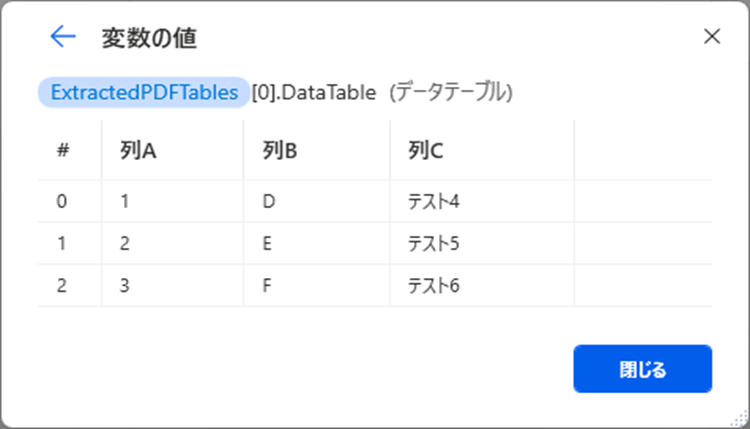
PDFファイルの2ページ目のデータテーブルが取得されていることが確認できます。
スポンサーリンク


